- Introduction to Machine Learning
- Model and Cost Function
- Gradient Decent
- Multivariate Linear Regression
- Classification
- Logistic Regression Model
- Overfitting & Regularization
- Neural Networks
- Back Propagation
- Back Propagation in Practice
- Evaluating a Learning Algorithm
- Bias vs. Variance
- Precision and Recall
Introduction to Machine Learning
What is Machine Learning?
Two definitions of Machine Learning are offered. Arthur Samuel described it as:
“the field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition.
Tom Mitchell provides a more modern definition:
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
In general, any machine learning problem can be assigned to one of two broad classifications:
Supervised learning and Unsupervised learning.
Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
Supervised learning problems are categorized into “regression” and “classification” problems. In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. In a classification problem, we are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
Example 1:
Given data about the size of houses on the real estate market, try to predict their price. Price as a function of size is a continuous output, so this is a regression problem.
We could turn this example into a classification problem by instead making our output about whether the house “sells for more or less than the asking price.” Here we are classifying the houses based on price into two discrete categories.
Example 2:
(a) Regression- Given a picture of a person, we have to predict their age on the basis of the given picture
(b) Classification - Given a patient with a tumor, we have to predict whether the tumor is malignant or benign.
So it actually have two kind of problems:
-
Regression: to predict a specific value
-
classification: to predict 0/1 problems
When the target variable that we’re trying to predict is continuous, such as in our housing example, we call the learning problem a regression problem. When y can take on only a small number of discrete values (such as if, given the living area, we wanted to predict if a dwelling is a house or an apartment, say), we call it a classification problem.
Unsupervised Learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
Example:
Clustering: Take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on.
Non-clustering: The “Cocktail Party Algorithm”, allows you to find structure in a chaotic environment. (i.e. identifying individual voices and music from a mesh of sounds at a cocktail party). ** Unsupervised learning does not predict the specific value or property, but instead it categories the data set, for example distinct all the circle from all the rectangle, or your voice from a mixed voice. **
Model and Cost Function
Model Representation
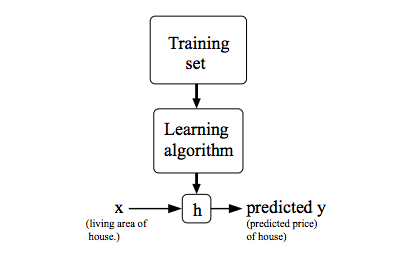
To establish notation for future use, we’ll use x(i) to denote the “input” variables (living area in this example), also called input features, and y(i) to denote the “output” or target variable that we are trying to predict (price). A pair (x(i), y(i)) is called a training example, and the dataset that we’ll be using to learn—a list of m training examples (x(i), y(i)); i=1 ,…, m - is called a training set. Note that the superscript “(i)” in the notation is simply an index into the training set, and has nothing to do with exponentiation. We will also use X to denote the space of input values, and Y to denote the space of output values. In this example, X = Y = ℝ.
To describe the supervised learning problem slightly more formally, our goal is, given a training set, to learn a function h : X → Y so that h(x) is a “good” predictor for the corresponding value of y. For historical reasons, this function h is called a hypothesis. Seen pictorially, the process is therefore like this:
Cost Function
We can measure the accuracy of our hypothesis function by using a cost function. This takes an average difference (actually a fancier version of an average) of all the results of the hypothesis with inputs from x’s and the actual output y’s.
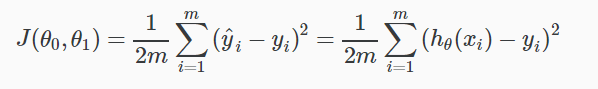
To break it apart, it is ½ x¯ where x¯ is the mean of the squares of hθ(xi) - yi , or the difference between the predicted value and the actual value.
This function is otherwise called the “Squared error function”, or “Mean squared error”. The mean is halved (½) as a convenience for the computation of the gradient descent, as the derivative term of the square function will cancel out the ½ term. The following image summarizes what the cost function does:

If we try to think of it in visual terms, our training data set is scattered on the x-y plane. We are trying to make a straight line (defined by hθ(x)) which passes through these scattered data points.
Our objective is to get the best possible line. The best possible line will be such so that the average squared vertical distances of the scattered points from the line will be the least. Ideally, the line should pass through all the points of our training data set. In such a case, the value of J(θ0, θ1) will be 0. The following example shows the ideal situation where we have a cost function of 0.
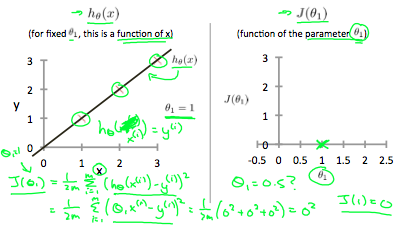
When θ1=1, we get a slope of 1 which goes through every single data point in our model. Conversely, when θ1=0.5, we see the vertical distance from our fit to the data points increase.
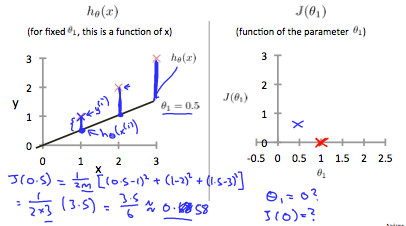
This increases our cost function to 0.58. Plotting several other points yields to the following graph:
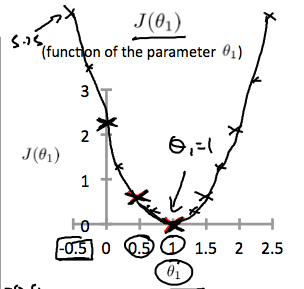
Thus as a goal, we should try to minimize the cost function. In this case, θ1=1 is our global minimum.
A contour plot is a graph that contains many contour lines. A contour line of a two variable function has a constant value at all points of the same line. An example of such a graph is the one to the right below.
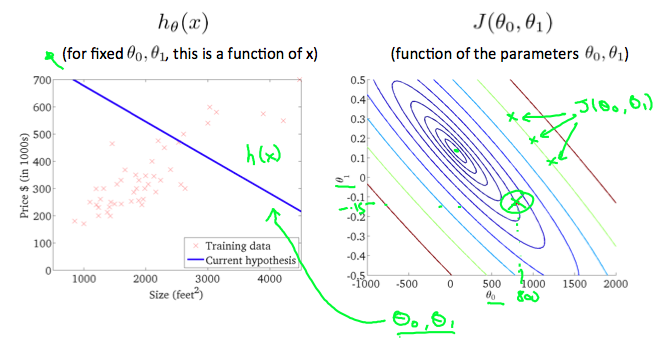
Taking any color and going along the ‘circle’, one would expect to get the same value of the cost function. For example, the three green points found on the green line above have the same value for J(θ0, θ1) and as a result, they are found along the same line. The circled x displays the value of the cost function for the graph on the left when θ0 = 800 and θ1= -0.15. Taking another h(x) and plotting its contour plot, one gets the following graphs:
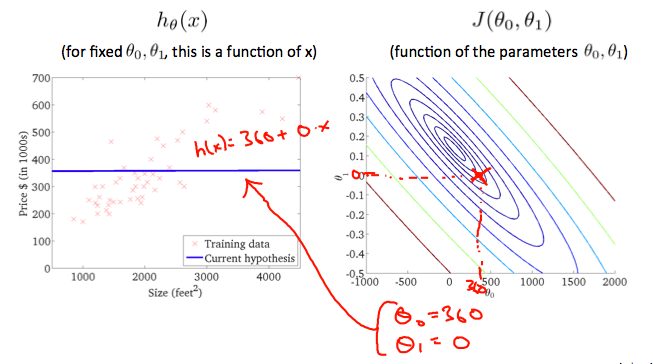
When θ0 = 360 and θ1 = 0, the value of J(θ0, θ1) in the contour plot gets closer to the center thus reducing the cost function error. Now giving our hypothesis function a slightly positive slope results in a better fit of the data.
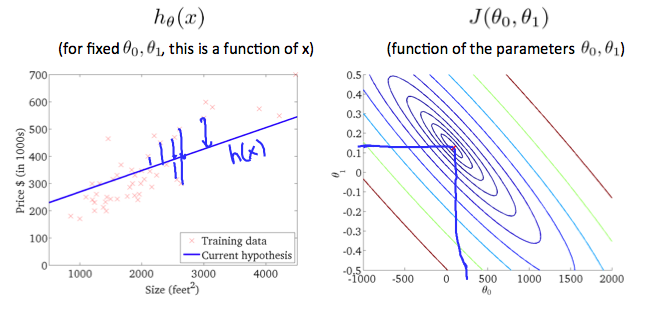
The graph above minimizes the cost function as much as possible and consequently, the result of θ1 and θ0 tend to be around 0.12 and 250 respectively. Plotting those values on our graph to the right seems to put our point in the center of the inner most ‘circle’.
Note: How to read this plot: The contour plot is actually a 3-D graph, and the center point is the lowest whereas the outside is higher. Consider as a bowl. And what we need is to find the lowest point, in this case (θ1, θ0) = (0.12, 250) ***
Gradient Decent
Now we have our hypothesis function and we have a way of measuring how well it fits into the data. Now we need to estimate the parameters in the hypothesis function. That’s where gradient descent comes in.
Imagine that we graph our hypothesis function based on its fields θ0 and θ1 (actually we are graphing the cost function as a function of the parameter estimates). We are not graphing x and y itself, but the parameter range of our hypothesis function and the cost resulting from selecting a particular set of parameters.
We put θ0 on the x axis and θ1 on the y axis, with the cost function on the vertical z axis. The points on our graph will be the result of the cost function using our hypothesis with those specific theta parameters. The graph below depicts such a setup.
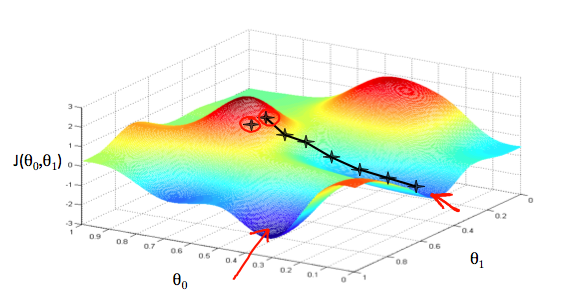
We will know that we have succeeded when our cost function is at the very bottom of the pits in our graph, i.e. when its value is the minimum. The red arrows show the minimum points in the graph.
The way we do this is by taking the derivative (the tangential line to a function) of our cost function. The slope of the tangent is the derivative at that point and it will give us a direction to move towards. We make steps down the cost function in the direction with the steepest descent. The size of each step is determined by the parameter α, which is called the learning rate.
For example, the distance between each ‘star’ in the graph above represents a step determined by our parameter α. A smaller α would result in a smaller step and a larger α results in a larger step. The direction in which the step is taken is determined by the partial derivative of J(θ0,θ1). Depending on where one starts on the graph, one could end up at different points. The image above shows us two different starting points that end up in two different places.
The gradient descent algorithm is:
repeat until convergence:
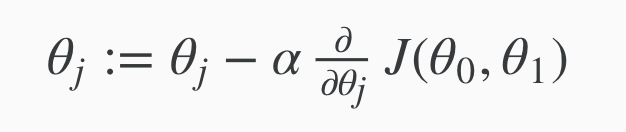
where j = 0,1 represents the feature index number.
At each iteration j, one should simultaneously update the parameters θ1, θ2,…, θn. Updating a specific parameter prior to calculating another one on the j(th) iteration would yield to a wrong implementation.

we explored the scenario where we used one parameter θ1 and plotted its cost function to implement a gradient descent. Our formula for a single parameter was :
Repeat until convergence:
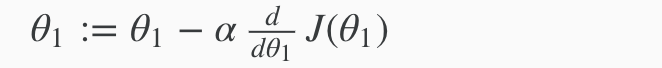
Regardless of the slope’s sign for d/dθ1J(θ1), θ1 eventually converges to its minimum value. The following graph shows that when the slope is negative, the value of θ1 increases and when it is positive, the value of θ1 decreases.
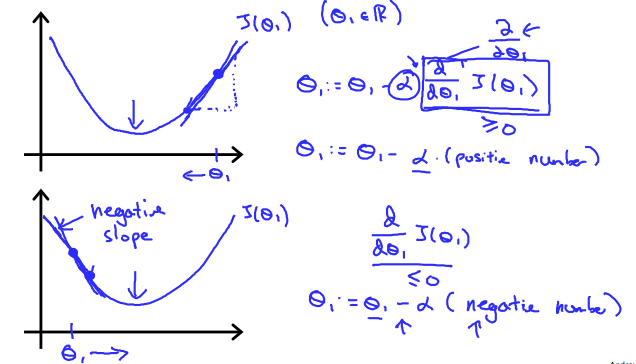
On a side note, we should adjust our parameter α to ensure that the gradient descent algorithm converges in a reasonable time. Failure to converge or too much time to obtain the minimum value imply that our step size is wrong.
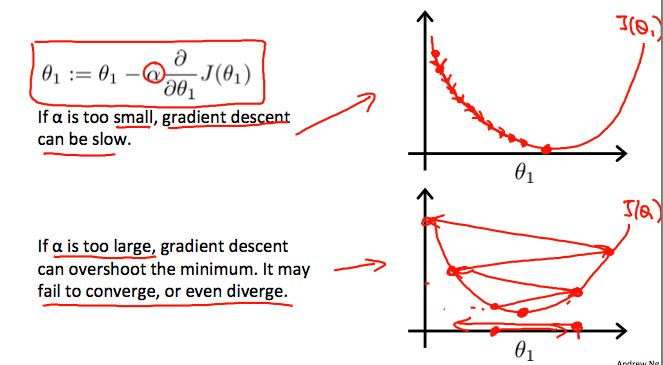
How does gradient descent converge with a fixed step size α?
The intuition behind the convergence is that d/dθ1J(θ1) approaches 0 as we approach the bottom of our convex function. At the minimum, the derivative will always be 0 and thus we get:
θ1 := θ1 - α*0
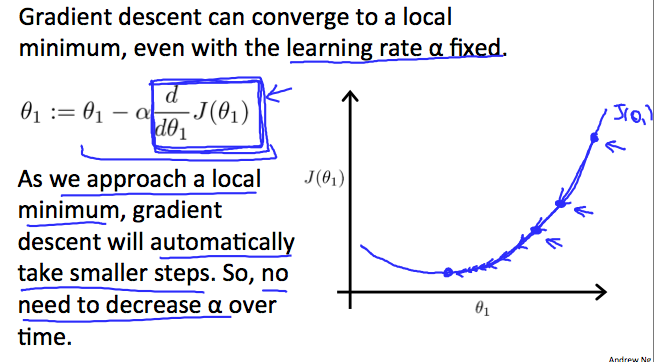
When specifically applied to the case of linear regression, a new form of the gradient descent equation can be derived. We can substitute our actual cost function and our actual hypothesis function and modify the equation to :
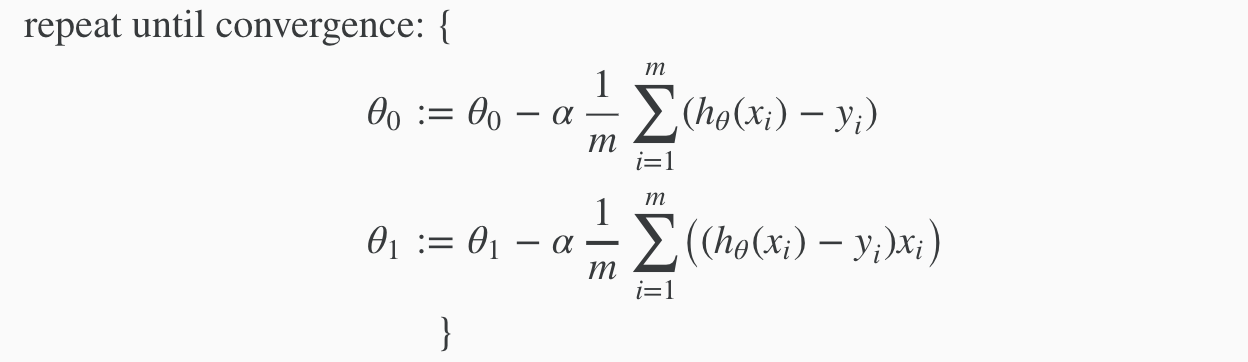
where m is the size of the training set, θ0 a constant that will be changing simultaneously with θ1 and xi ,yi are values of the given training set (data).
The point of all this is that if we start with a guess for our hypothesis and then repeatedly apply these gradient descent equations, our hypothesis will become more and more accurate.
So, this is simply gradient descent on the original cost function J. This method looks at every example in the entire training set on every step, and is called batch gradient descent. Note that, while gradient descent can be susceptible to local minima in general, the optimization problem we have posed here for linear regression has only one global, and no other local, optima; thus gradient descent always converges (assuming the learning rate α is not too large) to the global minimum. Indeed, J is a convex quadratic function. Here is an example of gradient descent as it is run to minimize a quadratic function.
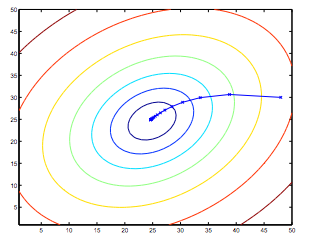
The ellipses shown above are the contours of a quadratic function. Also shown is the trajectory taken by gradient descent, which was initialized at (48,30). The x’s in the figure (joined by straight lines) mark the successive values of θ that gradient descent went through as it converged to its minimum.
Multivariate Linear Regression
Multiple Features
Linear regression with multiple variables is also known as “multivariate linear regression”.
We now introduce notation for equations where we can have any number of input variables.

The multivariable form of the hypothesis function accommodating these multiple features is as follows:
h(x) = θ0 + θ1x1 + θ2x2 + θ3x3 + ⋯ + θnxn
In order to develop intuition about this function, we can think about θ0 as the basic price of a house, θ01/sub> as the price per square meter, θ2 as the price per floor, etc. x1 will be the number of square meters in the house, x2 the number of floors, etc.
Using the definition of matrix multiplication, our multivariable hypothesis function can be concisely represented as:

This is a vectorization of our hypothesis function for one training example; see the lessons on vectorization to learn more.
Remark: Note that for convenience reasons in this course we assume x0(i) = 1 for (i∈1,…,m). This allows us to do matrix operations with θ and x. Hence making the two vectors ‘θ’ and x(i) match each other element-wise (that is, have the same number of elements: n+1).]
Gradient Descent For Multiple Variables
The gradient descent equation itself is generally the same form; we just have to repeat it for our ‘n’ features:
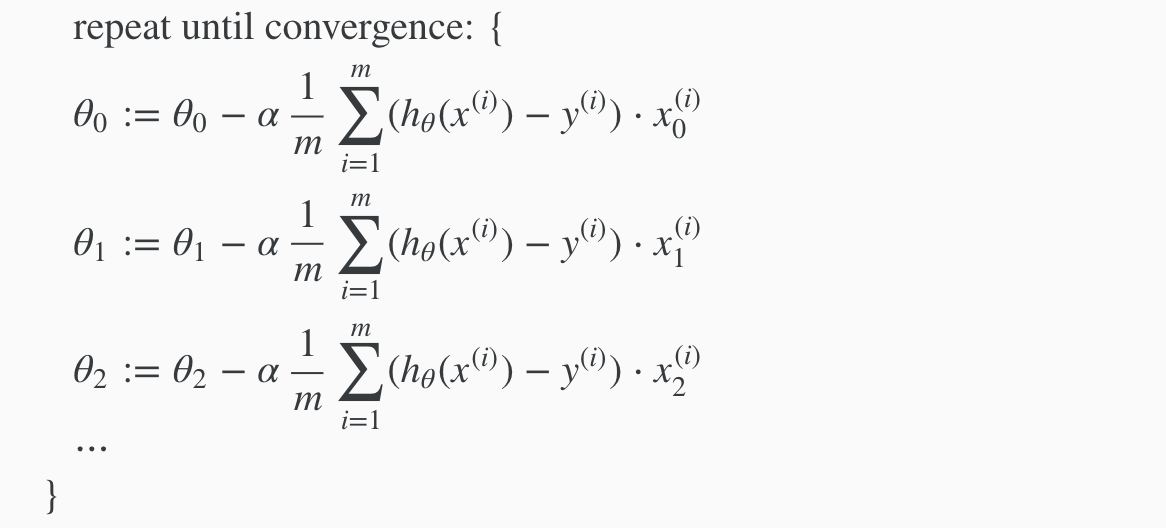
in other words:
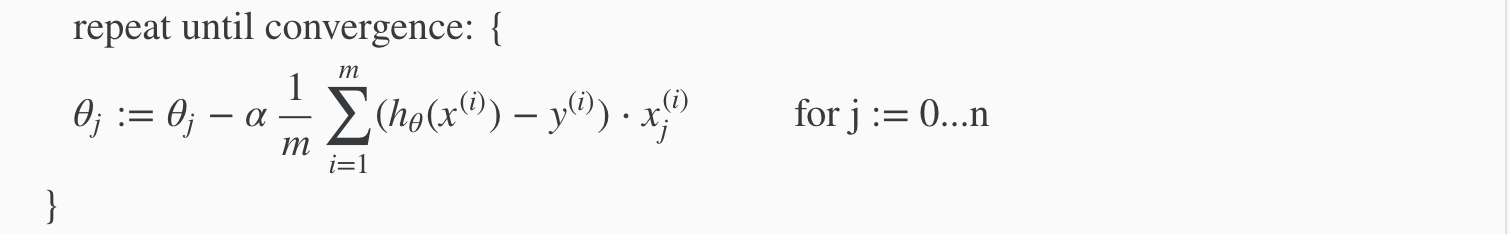
The following image compares gradient descent with one variable to gradient descent with multiple variables:

Feature Scaling
We can speed up gradient descent by having each of our input values in roughly the same range. This is because θ will descend quickly on small ranges and slowly on large ranges, and so will oscillate inefficiently down to the optimum when the variables are very uneven.
The way to prevent this is to modify the ranges of our input variables so that they are all roughly the same. Ideally:
−1 ≤ x(i) ≤ 1
or
−0.5 ≤ x(i) ≤ 0.5
These aren’t exact requirements; we are only trying to speed things up. The goal is to get all input variables into roughly one of these ranges, give or take a few.
Two techniques to help with this are feature scaling and mean normalization. Feature scaling involves dividing the input values by the range (i.e. the maximum value minus the minimum value) of the input variable, resulting in a new range of just 1. Mean normalization involves subtracting the average value for an input variable from the values for that input variable resulting in a new average value for the input variable of just zero. To implement both of these techniques, adjust your input values as shown in this formula:
xi := (xi - μi) / si
Where μi is the average of all the values for feature (i) and si is the range of values (max - min), or si is the standard deviation.
Note that dividing by the range, or dividing by the standard deviation, give different results. The quizzes in this course use range - the programming exercises use standard deviation.
For example, if xi represents housing prices with a range of 100 to 2000 and a mean value of 1000, then,
xi := (price − 1000)/1900.
Learning Rate
Debugging gradient descent. Make a plot with number of iterations on the x-axis. Now plot the cost function, J(θ) over the number of iterations of gradient descent. If J(θ) ever increases, then you probably need to decrease α.
Automatic convergence test. Declare convergence if J(θ) decreases by less than E in one iteration, where E is some small value such as 10−3. However in practice it’s difficult to choose this threshold value.
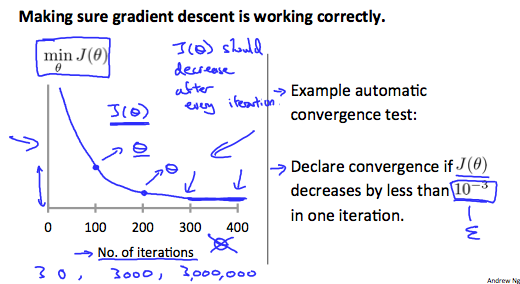
It has been proven that if learning rate α is sufficiently small, then J(θ) will decrease on every iteration.
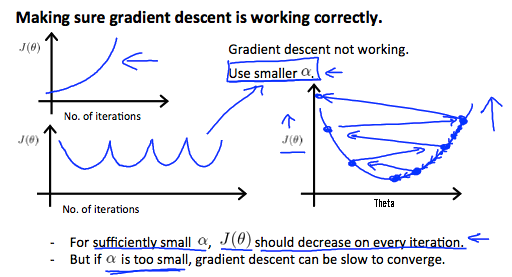
To summarize:
If α is too small: slow convergence.
If α is too large: may not decrease on every iteration and thus may not converge.
Polynomial Regression
Our hypothesis function need not be linear (a straight line) if that does not fit the data well.
We can change the behavior or curve of our hypothesis function by making it a quadratic, cubic or square root function (or any other form).
For example, if our hypothesis function is hθ(x)=θ0+θ1x1 then we can create additional features based on x1, to get the quadratic function hθ(x)=θ0+θ1x1+θ2x12 or the cubic function hθ(x)=θ0+θ1x1+θ2x12+θ3x13 In the cubic version, we have created new features x2 and x3 where x2=x12 and x3=x13.
To make it a square root function, we could do: hθ(x)=θ0+θ1x1+θ2*√x1 One important thing to keep in mind is, if you choose your features this way then feature scaling becomes very important.
eg. if x1 has range 1 - 1000 then range of x12 becomes 1 - 1000000 and that of x13 becomes 1 - 1000000000
Normal Equations
Gradient descent gives one way of minimizing J. Let’s discuss a second way of doing so, this time performing the minimization explicitly and without resorting to an iterative algorithm. In the “Normal Equation” method, we will minimize J by explicitly taking its derivatives with respect to the θj ’s, and setting them to zero. This allows us to find the optimum theta without iteration. The normal equation formula is given below:
θ=(XTX)−1XTy
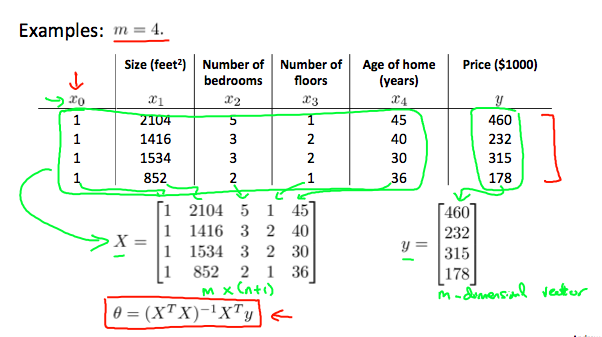
There is no need to do feature scaling with the normal equation.
The following is a comparison of gradient descent and the normal equation:

With the normal equation, computing the inversion has complexity O(n3). So if we have a very large number of features, the normal equation will be slow. In practice, when n exceeds 10,000 it might be a good time to go from a normal solution to an iterative process.
Classification
Classification
To attempt classification, one method is to use linear regression and map all predictions greater than 0.5 as a 1 and all less than 0.5 as a 0. However, this method doesn’t work well because classification is not actually a linear function.
The classification problem is just like the regression problem, except that the values we now want to predict take on only a small number of discrete values. For now, we will focus on the binary classification problem in which y can take on only two values, 0 and 1. (Most of what we say here will also generalize to the multiple-class case.) For instance, if we are trying to build a spam classifier for email, then x(i) may be some features of a piece of email, and y may be 1 if it is a piece of spam mail, and 0 otherwise. Hence, y∈{0,1}. 0 is also called the negative class, and 1 the positive class, and they are sometimes also denoted by the symbols “-” and “+.” Given x(i), the corresponding y(i) is also called the label for the training example.
Hypothesis Representation
We could approach the classification problem ignoring the fact that y is discrete-valued, and use our old linear regression algorithm to try to predict y given x. However, it is easy to construct examples where this method performs very poorly. Intuitively, it also doesn’t make sense for hθ(x) to take values larger than 1 or smaller than 0 when we know that y ∈ {0, 1}. To fix this, let’s change the form for our hypotheses hθ(x) to satisfy 0≤hθ(x)≤1. This is accomplished by plugging θTx into the Logistic Function.
Our new form uses the “Sigmoid Function,” also called the “Logistic Function”:

The following image shows us what the sigmoid function looks like:
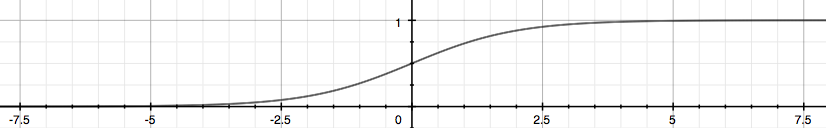
The function g(z), shown here, maps any real number to the (0, 1) interval, making it useful for transforming an arbitrary-valued function into a function better suited for classification.
hθ(x) will give us the probability that our output is 1. For example, hθ(x)=0.7 gives us a probability of 70% that our output is 1. Our probability that our prediction is 0 is just the complement of our probability that it is 1 (e.g. if probability that it is 1 is 70%, then the probability that it is 0 is 30%).
| hθ(x)=P(y=1 | x;θ)=1−P(y=0 | x;θ) |
| P(y=0 | x;θ)+P(y=1 | x;θ)=1 |
Decision Boundary
In order to get our discrete 0 or 1 classification, we can translate the output of the hypothesis function as follows:
hθ(x)≥0.5→y=1
hθ(x)<0.5→y=0
The way our logistic function g behaves is that when its input is greater than or equal to zero, its output is greater than or equal to 0.5:
g(z)≥0.5 when z≥0
So if our input to g is θTX, then that means:
hθ(x) = g(θTx) ≥ 0.5
when θTx ≥ 0
From these statements we can now say:
θTx ≥ 0 ⇒ y = 1
θTx < 0⇒ y = 0
The decision boundary is the line that separates the area where y = 0 and where y = 1. It is created by our hypothesis function.
Example
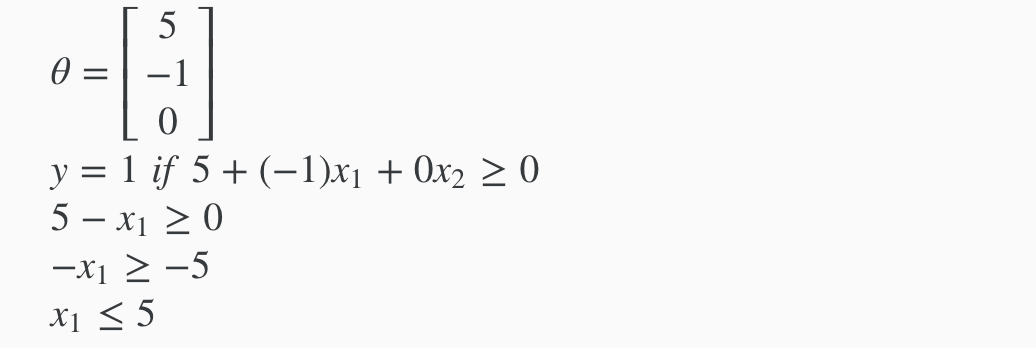
In this case, our decision boundary is a straight vertical line placed on the graph where x1=5, and everything to the left of that denotes y = 1, while everything to the right denotes y = 0.
Again, the input to the sigmoid function g(z) (e.g. θTX) doesn’t need to be linear, and could be a function that describes a circle (e.g. z=θ0+θ1x21+θ2x22) or any shape to fit our data.
Logistic Regression Model
Cost Function
We cannot use the same cost function that we use for linear regression because the Logistic Function will cause the output to be wavy, causing many local optima. In other words, it will not be a convex function.
Instead, our cost function for logistic regression looks like:
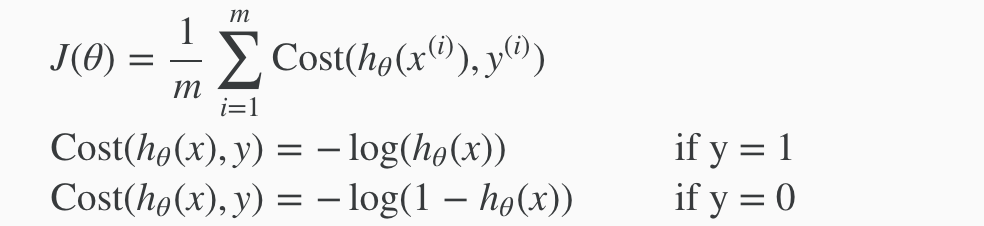
When y = 1, we get the following plot for J(θ) vs hθ(x):
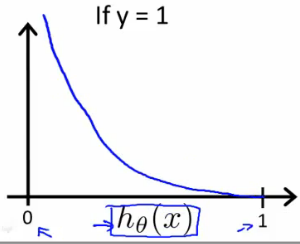
Similarly, when y = 0, we get the following plot for J(θ) vs hθ(x):
In summary:
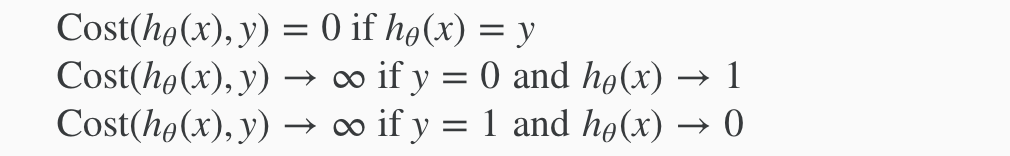
If our correct answer ‘y’ is 0, then the cost function will be 0 if our hypothesis function also outputs 0. If our hypothesis approaches 1, then the cost function will approach infinity.
If our correct answer ‘y’ is 1, then the cost function will be 0 if our hypothesis function outputs 1. If our hypothesis approaches 0, then the cost function will approach infinity.
Note that writing the cost function in this way guarantees that J(θ) is convex for logistic regression.
Simplified Cost Function and Gradient Descent
We can compress our cost function’s two conditional cases into one case:
Cost(hθ(x),y)= −y log(hθ(x))−(1−y)log(1−hθ(x))
Notice that when y is equal to 1, then the second term (1−y)log(1−hθ(x)) will be zero and will not affect the result. If y is equal to 0, then the first term −y log(hθ(x)) will be zero and will not affect the result.
We can fully write out our entire cost function as follows:
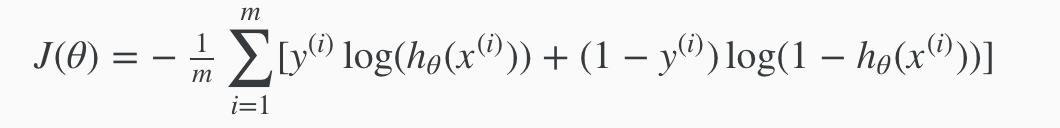
A vectorized implementation is:
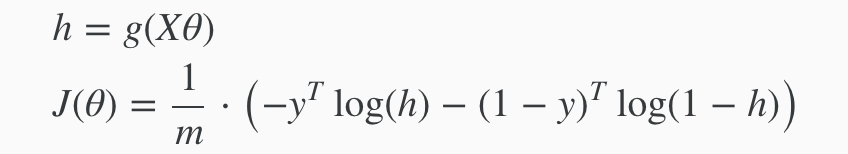
Remember that the general form of gradient descent is:
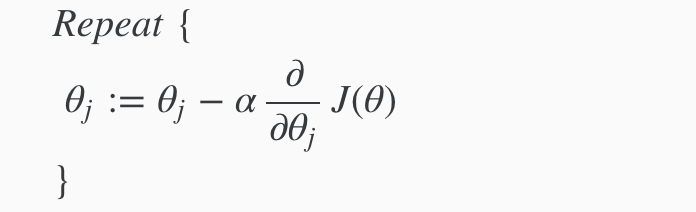
We can work out the derivative part using calculus to get:
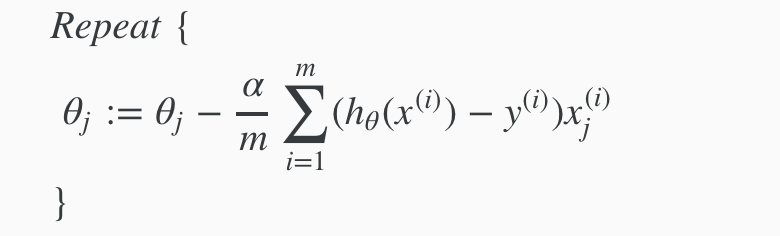
Notice that this algorithm is identical to the one we used in linear regression. We still have to simultaneously update all values in theta.
A vectorized implementation is:
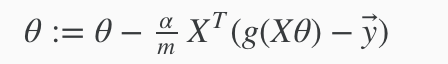
Multiclass Classification: One-vs-all
Now we will approach the classification of data when we have more than two categories. Instead of y = {0,1} we will expand our definition so that y = {0,1…n}.
Since y = {0,1…n}, we divide our problem into n+1 (+1 because the index starts at 0) binary classification problems; in each one, we predict the probability that ‘y’ is a member of one of our classes.
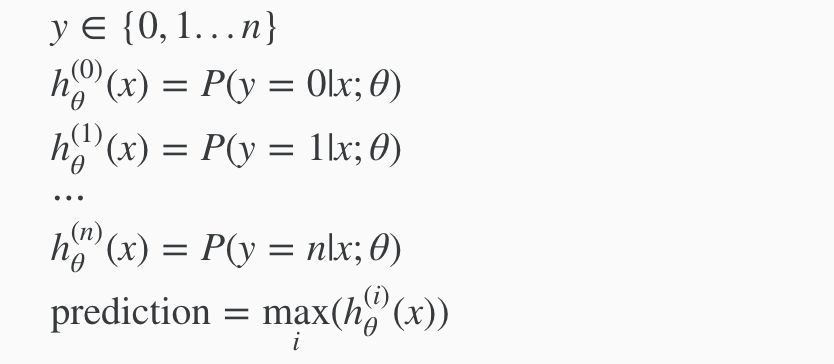
We are basically choosing one class and then lumping all the others into a single second class. We do this repeatedly, applying binary logistic regression to each case, and then use the hypothesis that returned the highest value as our prediction.
The following image shows how one could classify 3 classes:
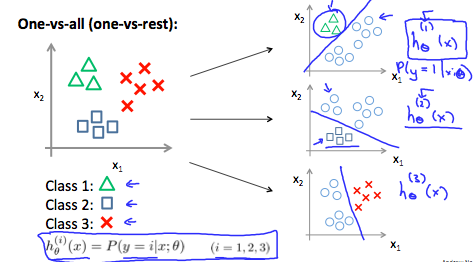
To summarize:
Train a logistic regression classifier hθ(x) for each class to predict the probability that  y = i .
To make a prediction on a new x, pick the class that maximizes hθ(x)
Overfitting & Regularization
The Problem of Overfitting
Consider the problem of predicting y from x ∈ R. The leftmost figure below shows the result of fitting a y = θ0+θ1x to a dataset. We see that the data doesn’t really lie on straight line, and so the fit is not very good.
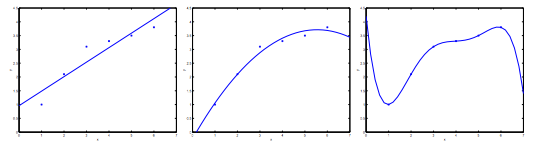
Instead, if we had added an extra feature x2 , and fit y=θ0+θ1x+θ2x2 , then we obtain a slightly better fit to the data (See middle figure). Naively, it might seem that the more features we add, the better. However, there is also a danger in adding too many features: The rightmost figure is the result of fitting a 5th order polynomial. We see that even though the fitted curve passes through the data perfectly, we would not expect this to be a very good predictor of, say, housing prices (y) for different living areas (x). Without formally defining what these terms mean, we’ll say the figure on the left shows an instance of underfitting—in which the data clearly shows structure not captured by the model—and the figure on the right is an example of overfitting.
Underfitting, or high bias, is when the form of our hypothesis function h maps poorly to the trend of the data. It is usually caused by a function that is too simple or uses too few features. At the other extreme, overfitting, or high variance, is caused by a hypothesis function that fits the available data but does not generalize well to predict new data. It is usually caused by a complicated function that creates a lot of unnecessary curves and angles unrelated to the data.
This terminology is applied to both linear and logistic regression. There are two main options to address the issue of overfitting:
1) Reduce the number of features:
Manually select which features to keep. Use a model selection algorithm (studied later in the course). 2) Regularization
Keep all the features, but reduce the magnitude of parameters θj. Regularization works well when we have a lot of slightly useful features.
Cost Function
If we have overfitting from our hypothesis function, we can reduce the weight that some of the terms in our function carry by increasing their cost.
Say we wanted to make the following function more quadratic:
θ0+θ1x+θ2x2+θ3x3+θ4x4
We’ll want to eliminate the influence of θ3x3 and θ4x4 . Without actually getting rid of these features or changing the form of our hypothesis, we can instead modify our cost function:
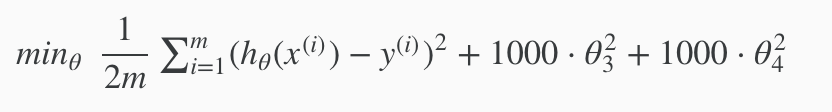
We’ve added two extra terms at the end to inflate the cost of θθ3 and θθ4. Now, in order for the cost function to get close to zero, we will have to reduce the values of θ3 and θ4 to near zero. This will in turn greatly reduce the values of θ3x3 and θ4x4 in our hypothesis function. As a result, we see that the new hypothesis (depicted by the pink curve) looks like a quadratic function but fits the data better due to the extra small terms θ3x3 and θ4x4.
This is the main idea about Regularization.
We could also regularize all of our theta parameters in a single summation as:
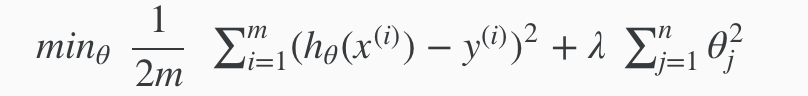
The λ, or lambda, is the regularization parameter. It determines how much the costs of our theta parameters are inflated.
Using the above cost function with the extra summation, we can smooth the output of our hypothesis function to reduce overfitting. If lambda is chosen to be too large, it may smooth out the function too much and cause underfitting. Hence, what would happen if λ=0 or is too small ?
Regularized Linear Regression
We will modify our gradient descent function to separate out θ0 from the rest of the parameters because we do not want to penalize θ0.
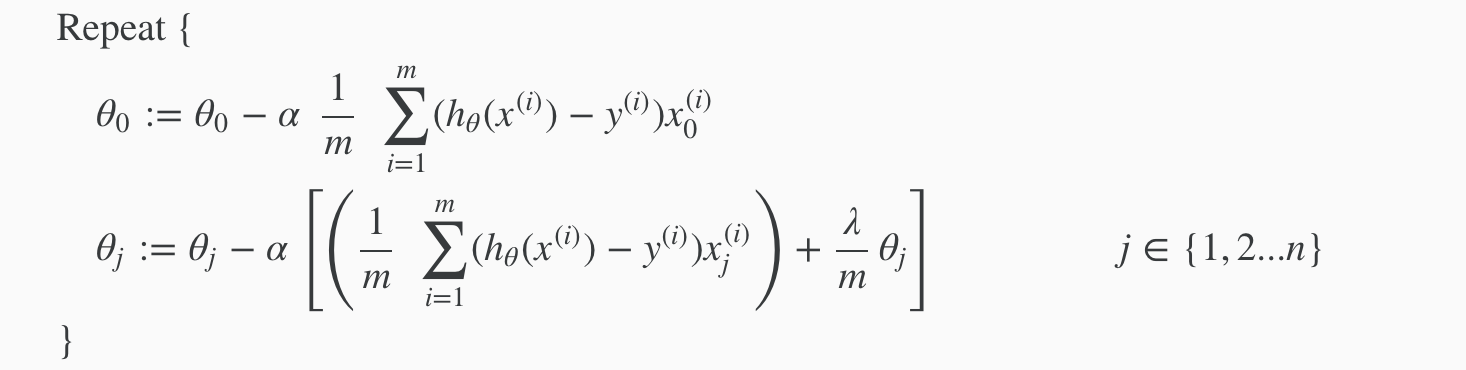
With some manipulation our update rule can also be represented as:
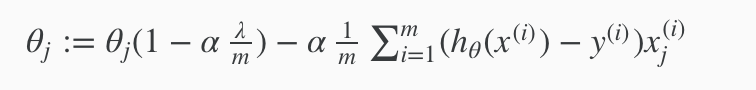
The first term in the above equation, 1−αλ/m will always be less than 1. Intuitively you can see it as reducing the value of θj by some amount on every update. Notice that the second term is now exactly the same as it was before.
Normal Equation
To add in regularization, the equation is the same as our original, except that we add another term inside the parentheses:
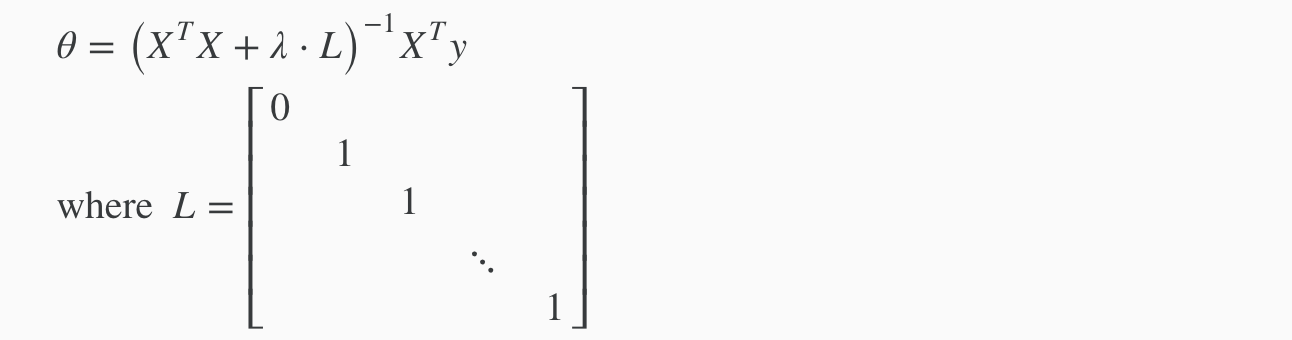
L is a matrix with 0 at the top left and 1’s down the diagonal, with 0’s everywhere else. It should have dimension (n+1)×(n+1). Intuitively, this is the identity matrix (though we are not including x0), multiplied with a single real number λ.
Regularized Logistic Regression
We can regularize logistic regression in a similar way that we regularize linear regression. As a result, we can avoid overfitting. The following image shows how the regularized function, displayed by the pink line, is less likely to overfit than the non-regularized function represented by the blue line:
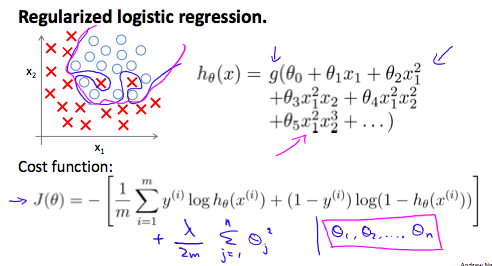
Recall that our cost function for logistic regression was:
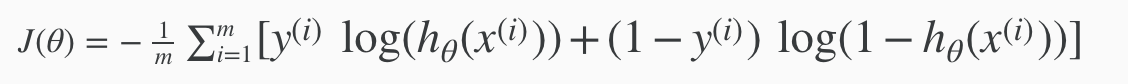
We can regularize this equation by adding a term to the end:
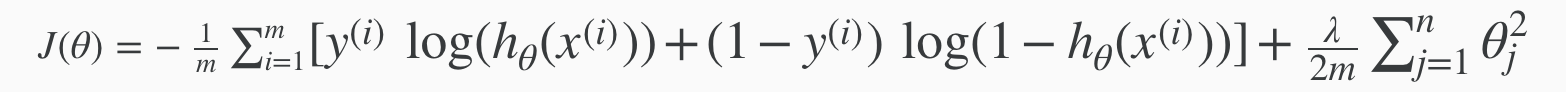


Neural Networks
Model Representation
Let’s examine how we will represent a hypothesis function using neural networks. At a very simple level, neurons are basically computational units that take inputs (dendrites) as electrical inputs (called “spikes”) that are channeled to outputs (axons). In our model, our dendrites are like the input features x1 ⋯ xn, and the output is the result of our hypothesis function. In this model our x0 input node is sometimes called the “bias unit.” It is always equal to 1. In neural networks, we use the same logistic function as in classification, 1/1+e−θTx, yet we sometimes call it a sigmoid (logistic) activation function. In this situation, our “theta” parameters are sometimes called “weights”.
Visually, a simplistic representation looks like:
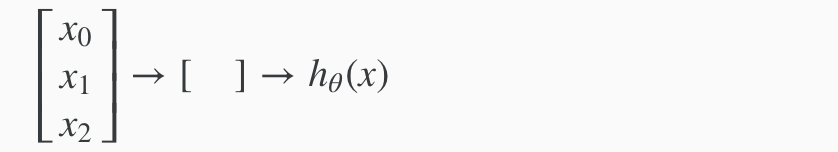
Our input nodes (layer 1), also known as the “input layer”, go into another node (layer 2), which finally outputs the hypothesis function, known as the “output layer”.
We can have intermediate layers of nodes between the input and output layers called the “hidden layers.”
In this example, we label these intermediate or “hidden” layer nodes a20⋯a2n and call them “activation units.”
If we had one hidden layer, it would look like:
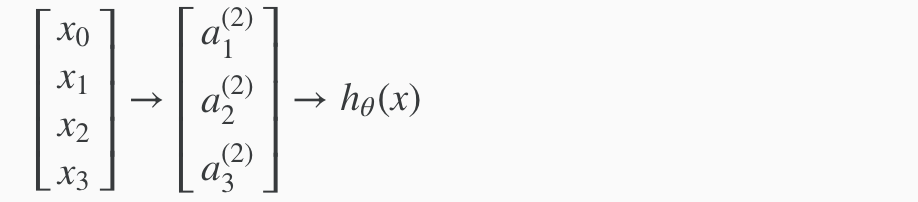
The values for each of the “activation” nodes is obtained as follows:
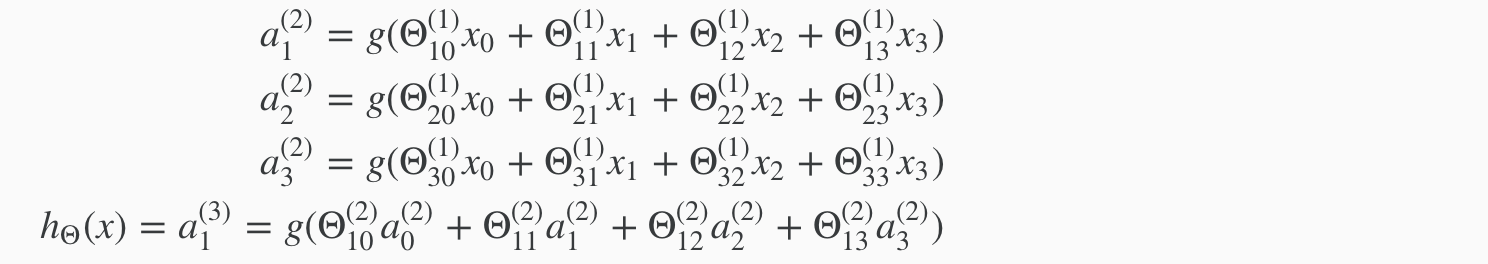
This is saying that we compute our activation nodes by using a 3×4 matrix of parameters. We apply each row of the parameters to our inputs to obtain the value for one activation node. Our hypothesis output is the logistic function applied to the sum of the values of our activation nodes, which have been multiplied by yet another parameter matrix Θ(2) containing the weights for our second layer of nodes.
Each layer gets its own matrix of weights, Θ(j).
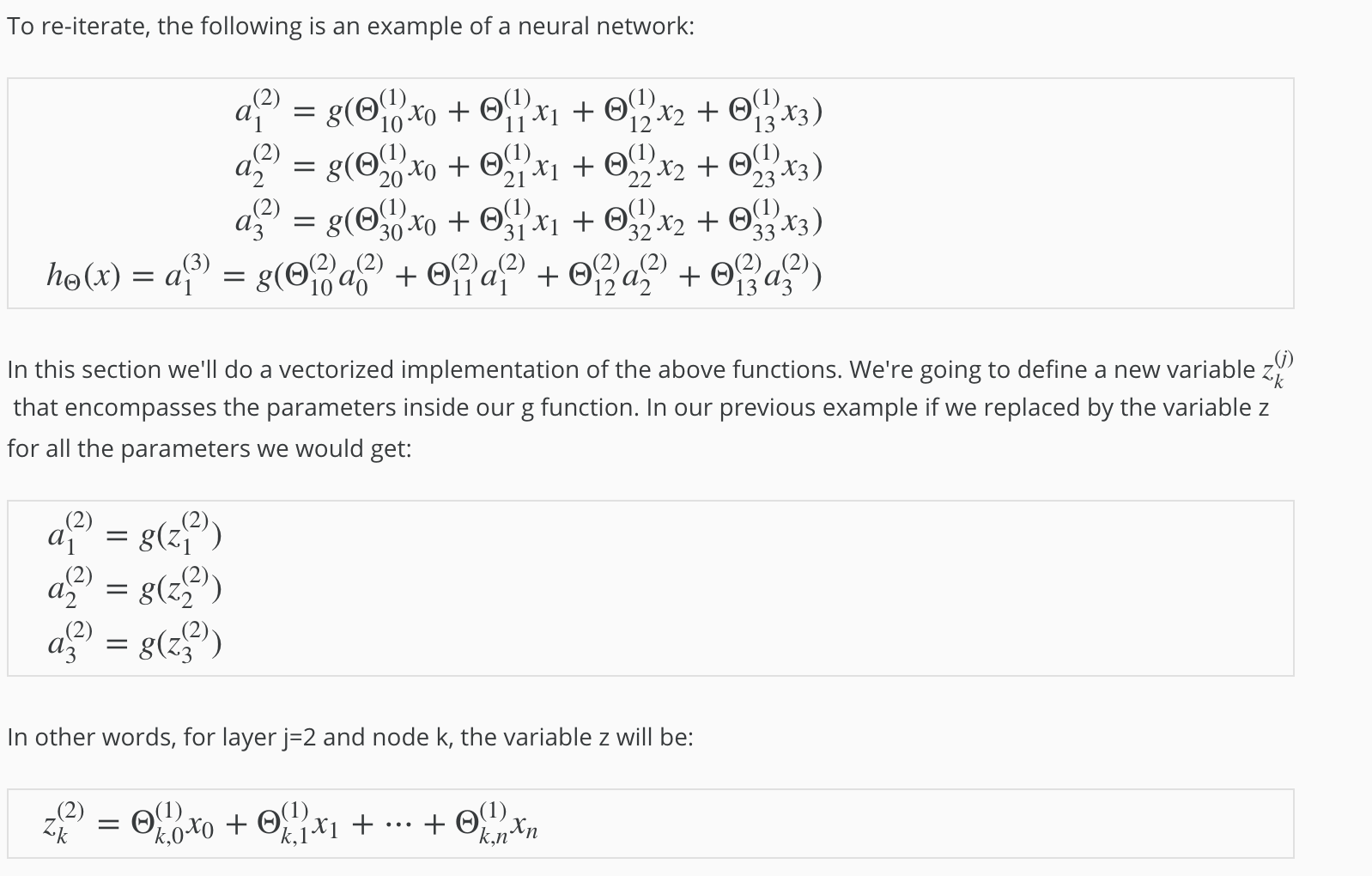
The dimensions of these matrices of weights is determined as follows:
If network has sj units in layer j and sj+1 units in layer j+1, then Θ(j) will be of dimension sj+1 × (sj+1). The +1 comes from the addition in Θ(j) of the “bias nodes,” x0 and Θ(j)0. In other words the output nodes will not include the bias nodes while the inputs will. The following image summarizes our model representation:




Back Propagation
Cost Function
Let’s first define a few variables that we will need to use:
- L = total number of layers in the network
- sl = number of units (not counting bias unit) in layer l
- K = number of output units/classes
Recall that in neural networks, we may have many output nodes. We denote hΘ(x)k as being a hypothesis that results in the kth output. Our cost function for neural networks is going to be a generalization of the one we used for logistic regression. Recall that the cost function for regularized logistic regression was:
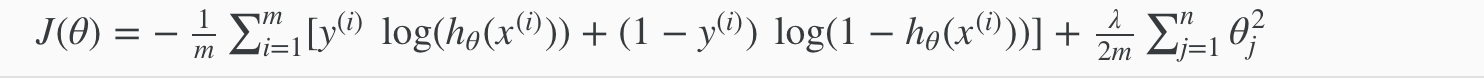
For neural networks, it is going to be slightly more complicated:
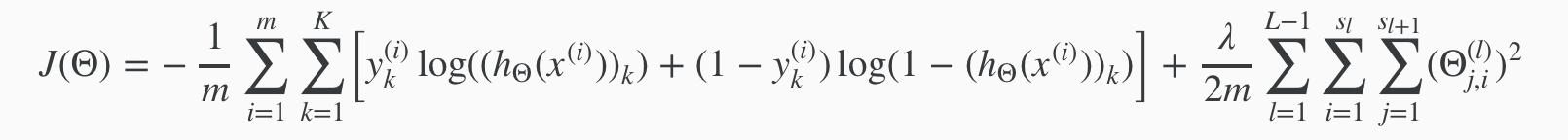
We have added a few nested summations to account for our multiple output nodes. In the first part of the equation, before the square brackets, we have an additional nested summation that loops through the number of output nodes.
In the regularization part, after the square brackets, we must account for multiple theta matrices. The number of columns in our current theta matrix is equal to the number of nodes in our current layer (including the bias unit). The number of rows in our current theta matrix is equal to the number of nodes in the next layer (excluding the bias unit). As before with logistic regression, we square every term.
Note:
- the double sum simply adds up the logistic regression costs calculated for each cell in the output layer
- the triple sum simply adds up the squares of all the individual Θs in the entire network.
- the i in the triple sum does not refer to training example i
Back Propagation Algorithm
“Backpropagation” is neural-network terminology for minimizing our cost function, just like what we were doing with gradient descent in logistic and linear regression. Our goal is to compute:
minΘJ(Θ)
That is, we want to minimize our cost function J using an optimal set of parameters in theta. In this section we’ll look at the equations we use to compute the partial derivative of J(Θ):

To do so, we use the following algorithm:




Back Propagation Intuition

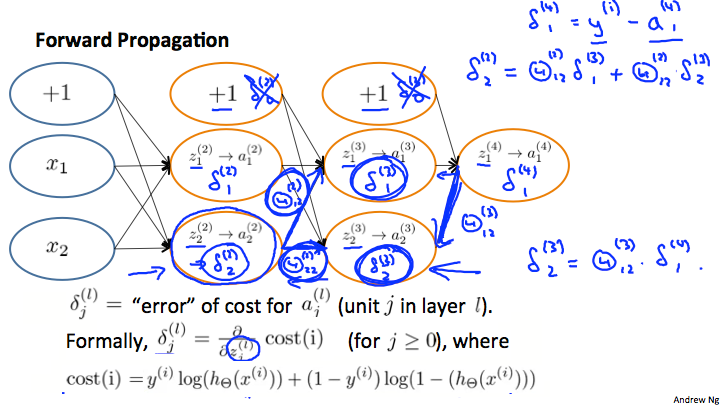

Back Propagation in Practice
Gradient Checking

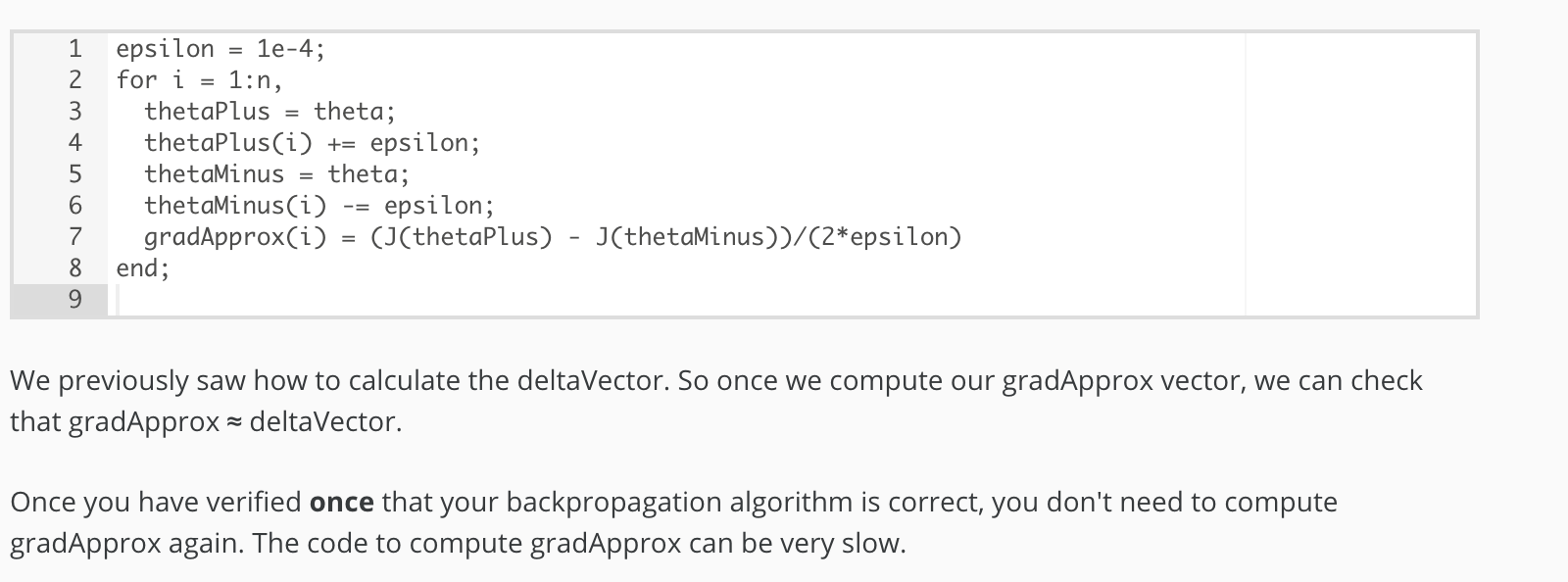
Random Initialization
Initializing all theta weights to zero does not work with neural networks. When we backpropagate, all nodes will update to the same value repeatedly. Instead we can randomly initialize our weights for our Θ matrices using the following method:


Putting it Together
First, pick a network architecture; choose the layout of your neural network, including how many hidden units in each layer and how many layers in total you want to have.
- Number of input units = dimension of features x(i)
- Number of output units = number of classes
- Number of hidden units per layer = usually more the better (must balance with cost of computation as it increases with more hidden units)
- Defaults: 1 hidden layer. If you have more than 1 hidden layer, then it is recommended that you have the same number of units in every hidden layer.
Training a Neural Network
- Randomly initialize the weights
- Implement forward propagation to get hΘ(x(i)) for any x(i)
- Implement the cost function
- Implement backpropagation to compute partial derivatives
- Use gradient checking to confirm that your backpropagation works. Then disable gradient checking.
- Use gradient descent or a built-in optimization function to minimize the cost function with the weights in theta.
When we perform forward and back propagation, we loop on every training example:
for i = 1:m,
Perform forward propagation and backpropagation using example (x(i),y(i))
(Get activations a(l) and delta terms d(l) for l = 2,...,L
The following image gives us an intuition of what is happening as we are implementing our neural network:
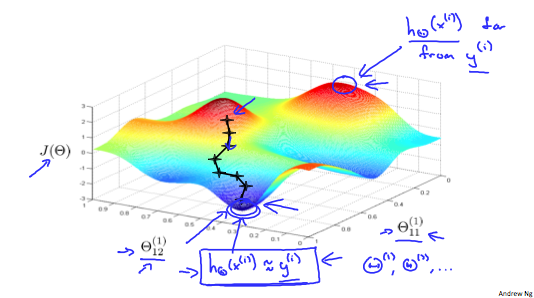
Ideally, you want hΘ(x(i)) ≈ y(i). This will minimize our cost function. However, keep in mind that J(Θ) is not convex and thus we can end up in a local minimum instead.
Evaluating a Learning Algorithm
Evaluating a Hypothesis
Once we have done some trouble shooting for errors in our predictions by:
- Getting more training examples
- Trying smaller sets of features
- Trying additional features
- Trying polynomial features
- Increasing or decreasing λ
We can move on to evaluate our new hypothesis.
A hypothesis may have a low error for the training examples but still be inaccurate (because of overfitting). Thus, to evaluate a hypothesis, given a dataset of training examples, we can split up the data into two sets: a training set and a test set. Typically, the training set consists of 70 % of your data and the test set is the remaining 30 %.
The new procedure using these two sets is then:
- Learn Θ and minimize Jtrain(Θ) using the training set
- Compute the test set error Jtest(Θ)

Model Selection and Train/Validation/Test Sets
Just because a learning algorithm fits a training set well, that does not mean it is a good hypothesis. It could over fit and as a result your predictions on the test set would be poor. The error of your hypothesis as measured on the data set with which you trained the parameters will be lower than the error on any other data set.
Given many models with different polynomial degrees, we can use a systematic approach to identify the ‘best’ function. In order to choose the model of your hypothesis, you can test each degree of polynomial and look at the error result.
One way to break down our dataset into the three sets is:
- Training set: 60%
- Cross validation set: 20%
- Test set: 20%
We can now calculate three separate error values for the three different sets using the following method:
- Optimize the parameters in Θ using the training set for each polynomial degree.
- Find the polynomial degree d with the least error using the cross validation set.
- Estimate the generalization error using the test set with Jtest(Θ(d)), (d = theta from polynomial with lower error);
This way, the degree of the polynomial d has not been trained using the test set.

Bias vs. Variance
Diagnosing Bias vs. Variance
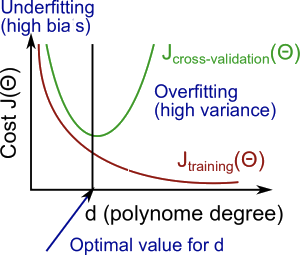
In this section we examine the relationship between the degree of the polynomial d and the underfitting or overfitting of our hypothesis.
We need to distinguish whether bias or variance is the problem contributing to bad predictions. High bias is underfitting and high variance is overfitting. Ideally, we need to find a golden mean between these two. The training error will tend to decrease as we increase the degree d of the polynomial.
At the same time, the cross validation error will tend to decrease as we increase d up to a point, and then it will increase as d is increased, forming a convex curve.
High bias (underfitting): both Jtrain(Θ) and JCV(Θ) will be high. Also, JCV(Θ)≈Jtrain(Θ).
High variance (overfitting): Jtrain(Θ) will be low and JCV(Θ) will be much greater than Jtrain(Θ).
The is summarized in the figure below:
Regularization and Bias/Variance
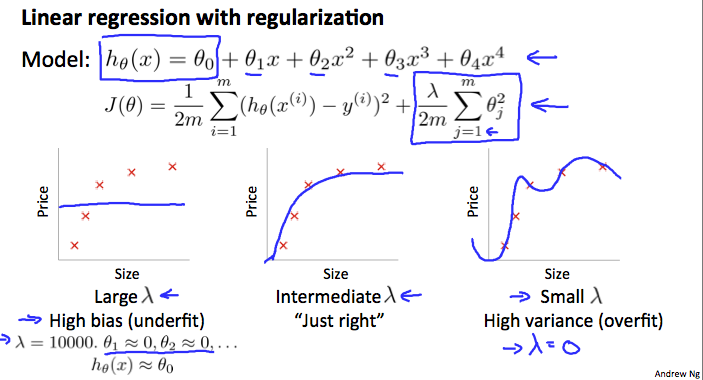
In the figure above, we see that as λ increases, our fit becomes more rigid. On the other hand, as λ approaches 0, we tend to over overfit the data. So how do we choose our parameter λ to get it ‘just right’ ? In order to choose the model and the regularization term λ, we need to:
- Create a list of lambdas (i.e. λ∈{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24});
- Create a set of models with different degrees or any other variants.
- Iterate through the λs and for each λ go through all the models to learn some Θ.
- Compute the cross validation error using the learned Θ (computed with λ) on the JCV(Θ) without regularization or λ = 0.
- Select the best combo that produces the lowest error on the cross validation set.
- Using the best combo Θ and λ, apply it on Jtest(Θ) to see if it has a good generalization of the problem.
Learning Curves
Training an algorithm on a very few number of data points (such as 1, 2 or 3) will easily have 0 errors because we can always find a quadratic curve that touches exactly those number of points. Hence:
- As the training set gets larger, the error for a quadratic function increases.
- The error value will plateau out after a certain m, or training set size.
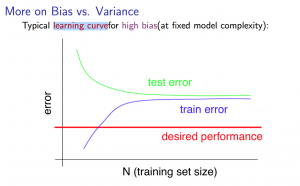
Experiencing high bias:
Low training set size: causes Jtrain(Θ) to be low and JCV(Θ) to be high.
Large training set size: causes both Jtrain(Θ) and JCV(Θ) to be high with Jtrain(Θ)≈JCV(Θ).
If a learning algorithm is suffering from high bias, getting more training data will not (by itself) help much.
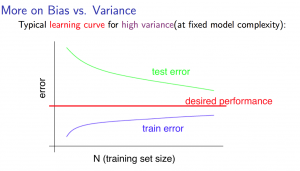
Experiencing high variance:
Low training set size: Jtrain(Θ) will be low and JCV(Θ) will be high.
Large training set size: Jtrain(Θ) increases with training set size and JCV(Θ) continues to decrease without leveling off. Also, Jtrain(Θ) < JCV(Θ) but the difference between them remains significant.
If a learning algorithm is suffering from high variance, getting more training data is likely to help.
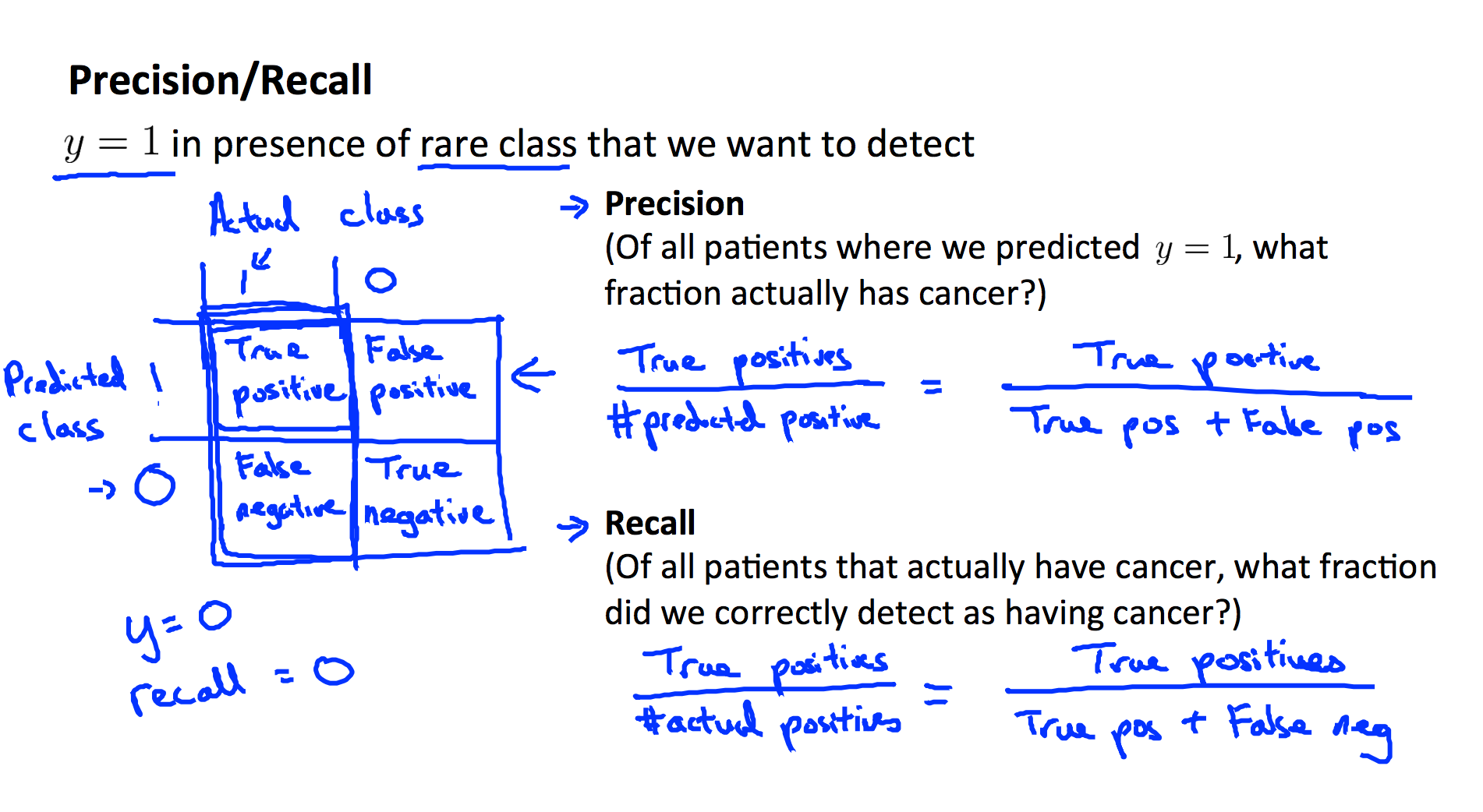
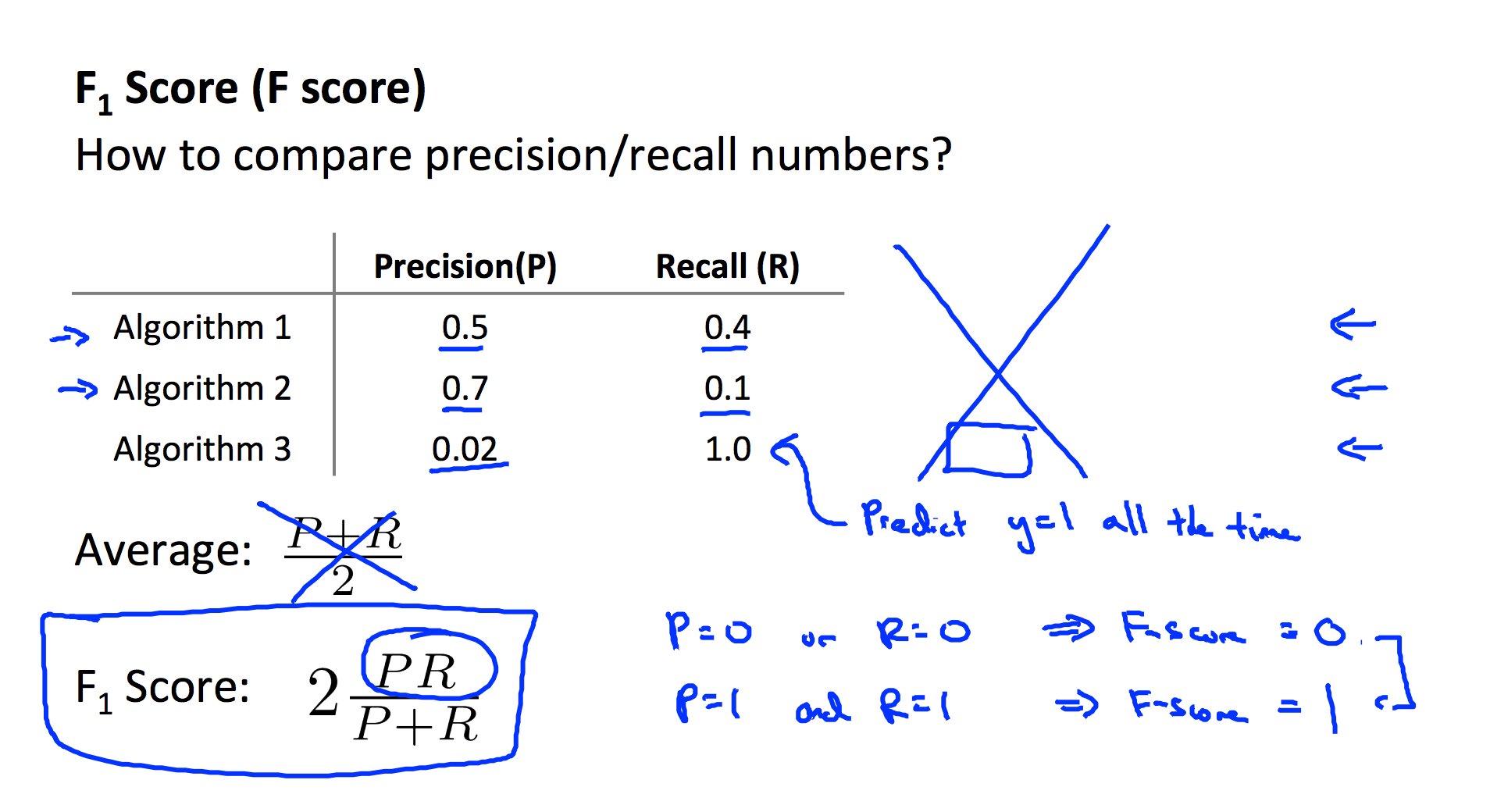
Precision and Recall