- What is Operating System
- Virtualization
- The Process
- Process States
- Interlude: Process API
- Mechanism: Limited Direct Execution
- Scheduling: Introduction
- Scheduling: The Multi-Level Feedback Queue (MLFQ)
- Scheduling: Proportional Share
- The Abstraction: Address Spaces
- Mechanism: Address Translation
- 16.Segmentation
- 17.Free-Space Management
- 18.paging
- 19.Paging: Faster Translations (TLBs)
- 20.Paging: Smaller Tables
- 21.Beyond Physical Memory: Mechanisms
- 22.Beyond Physical Memory: Policies
- The Real Life
- Concurrency
Recently I found OS very important when I was strying to optimize the program I wrote which is incredibly slow. By understanding OS I could be more aware of the concurrency and other part of the computer.
This blog is basicly a summary for each chapter and also a review for thr future me.
What is Operating System
What program does
It executes instructions. Many millions (and these days, even billions) of times every second, the processor fetches an instruction from memory, decodes it (i.e., figures out which instruction this is), and executes it (i.e., it does the thing that it is supposed to do, like add two numbers together, access memory, check a condition, jump to a function, and so forth). After it is done with this instruction, the processor moves on to the next instruction, and so on, and so on, until the program finally completes.
Virtualizing the CPU
Even though we have only one processor, somehow all four of these programs seem to be running at the same time. the role of the OS as a resource manager.
Virtualizing the memory
It is as if each running program has its own private memory, instead of sharing the same physical memory with other running programs. Each process accesses its own private virtual address space.
Concurrency
multi-threaded programs
Persistence
input/output or I/O device
file system is responsible for storing any files the user creates in a reliable and efficient manner on the disks of the system.
Design Goal
it takes physical resources, such as a CPU, memory, or disk, and virtualizes them. It handles tough and tricky issues related to concurrency. And it stores files persistently, thus making them safe over the long-term.
Virtualization
The Process
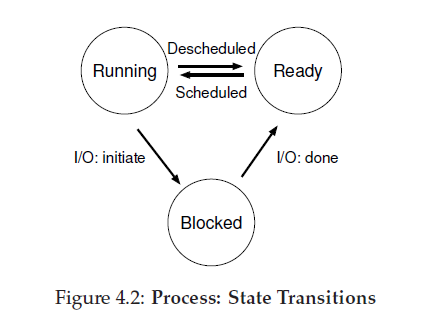
Process States
1.running
In the running state, a process is running on a processor. This means it is executing instructions.
2.Ready
In the ready state, a process is ready to run but for some reason the OS has chosen not to run it at this given moment.
3.Blocked
In the blocked state, a process has performed some kind of operation that makes it not ready to run until some other event takes place.
Interlude: Process API
UNIX presents one of the most intriguing ways to create a new process with a pair of system calls: fork() and exec(). A third routine, wait(), can be used by a process wishing to wait for a process it has created to complete.
fork()
The fork() system call is used to create a new process.
system call, which the OS provides as a way to create a new process. The odd part: the process that is created is an (almost) exact copy of the calling process. That means that to the OS, it now looks like there are two copies of the program p1 running, and both are about to return from the fork() systemcall. The newly-created process (called the child, in contrast to the creating parent) doesn’t start running at main(), like you might expect (note, the “hello, world” message only got printed out once); rather, it just comes into life as if it had called fork() itself.
wait()
if the parent does happen to run first, it will immediately call wait(); this system call won’t return until the child has run and exited. Thus, even when the parent runs first, it politely waits for the child to finish running, then wait() returns, and then the parent prints its message.
exec()
This system call is useful when you want to run a program that is different from the calling program.
call is strange; its partner in crime, exec(), is not so normal either. What it does: given the name of an executable (e.g., wc), and some arguments (e.g., p3.c), it loads code (and static data) from that executable and overwrites its current code segment (and current static data) with it; the heap and stack and other parts of the memory space of the program are re-initialized. Then the OS simply runs that program, passing in any arguments as the argv of that process. Thus, it does not create a new process; rather, it transforms the currently running program (formerly p3) into a different running program (wc). After the exec() in the child, it is almost as if p3.c never ran; a successful call to exec() never returns.
Mechanism: Limited Direct Execution
Basic Technique: Limited Direct Execution
just run the program directly on the CPU. Thus, when the OS wishes to start a program running, it creates a process entry for it in a process list, allocates somememory for it, loads the programcode intomemory (from disk), locates its entry point (i.e., the main() routine or something similar), jumps to it, and starts running the user’s code. Figure 6.1 shows this basic direct execution protocol (without any limits, yet), using a normal call and return to jump to the program’s main() and later to get back into the kernel.

Problem #1: Restricted Operations
There are two modes: user mode and kernel mode.
user mode: code that runs in user mode is restricted in what it can do. For example, when running in user mode, a process can’t issue I/O requests; doing so would result in the processor raising an exception; the OS would then likely kill the process.
kernel mode: which the operating system (or kernel) runs in. In this mode, code that runs can do what it likes, including privileged operations such as issuing I/O requests and executing all types of restricted instructions.
LDE protocol
There are two phases in the LDE protocol. In the first (at boot time), the kernel initializes the trap table, and the CPU remembers its location for subsequent use. The kernel does so via a privileged instruction (all privileged instructions are highlighted in bold).
In the second (when running a process), the kernel sets up a fewthings (e.g., allocating a node on the process list, allocating memory) before using a return-from-trap instruction to start the execution of the process; this switches the CPU to user mode and begins running the process. When the process wishes to issue a system call, it traps back into the OS, which handles it and once again returns control via a return-from-trap to the process. The process then completes its work, and returns from main(); this usually will return into some stub code which will properly exit the program(say, by calling the exit() system call, which traps into the OS). At this point, the OS cleans up and we are done.

Problem #2: Switching Between Processes
A Cooperative Approach: Wait For System Calls
the OS trusts the processes of the system to behave reasonably. Processes that run for too long are assumed to periodically give up the CPU so that the OS can decide to run some other task.
Applications also transfer control to the OS when they do something illegal. For example, if an application divides by zero, or tries to access memory that it shouldn’t be able to access, it will generate a trap to the OS. The OS will then have control of the CPU again (and likely terminate the offending process).
Thus, in a cooperative scheduling system, the OS regains control of the CPU by waiting for a system call or an illegal operation of some kind to take place.
A Non-Cooperative Approach: The OS Takes Control
A timer device can be programmed to raise an interrupt every so many milliseconds; when the interrupt is raised, the currently running process is halted, and a pre-configured interrupt handler in the OS runs. At this point, the OS has regained control of the CPU, and thus can do what it pleases: stop the current process, and start a different one.
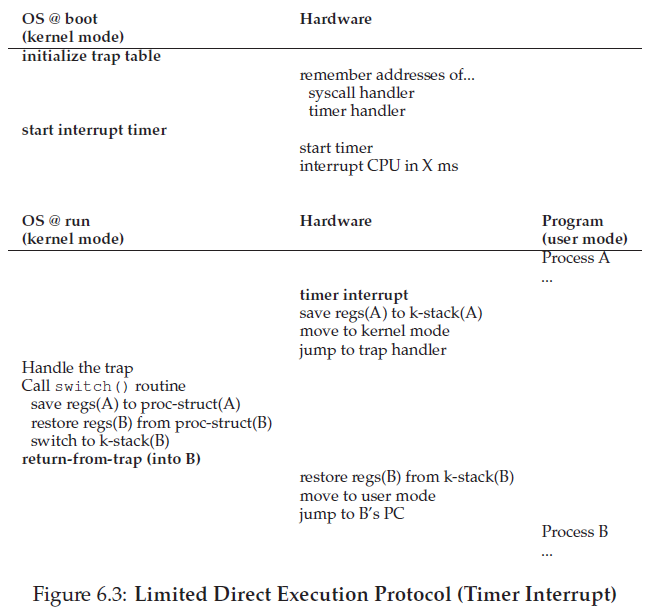
Saving and Restoring Context
A context switch is conceptually simple: all the OS has to do is save a few register values for the currently-executing process (onto its kernel stack, for example) and restore a few for the soon-to-be-executing process (from its kernel stack).
Scheduling: Introduction
First there are two definations:
Tturnaround = Tcompletion − Tarrival
Tresponse = Tfirstrun − Tarrival
First In, First Out (FIFO)
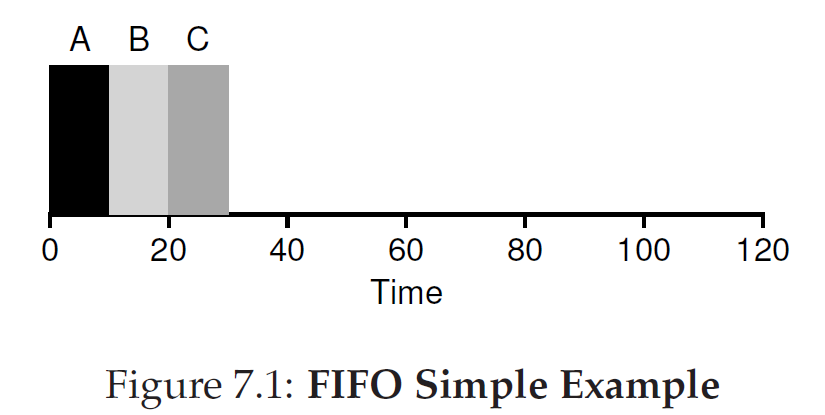
This problemis generally referred to as the convoy effect, where a number of relatively-short potential consumers of a resource get queued behind a heavyweight resource consumer.
Shortest Job First (SJF)
it runs the shortest job first, then the next shortest, and so on.
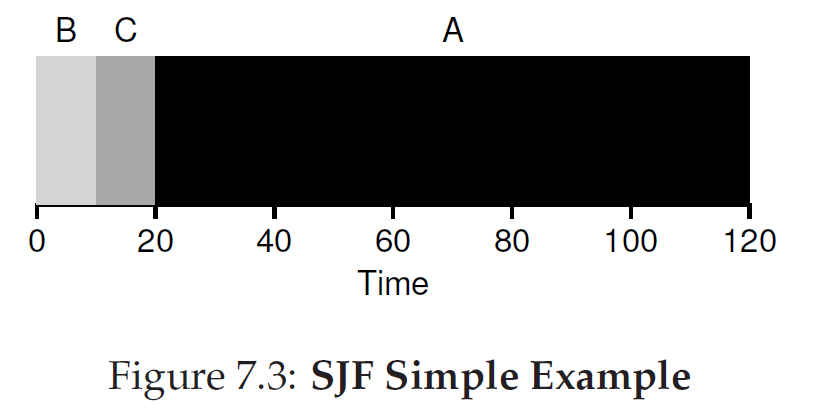
here comes the problem:

Shortest Time-to-Completion First (STCF)
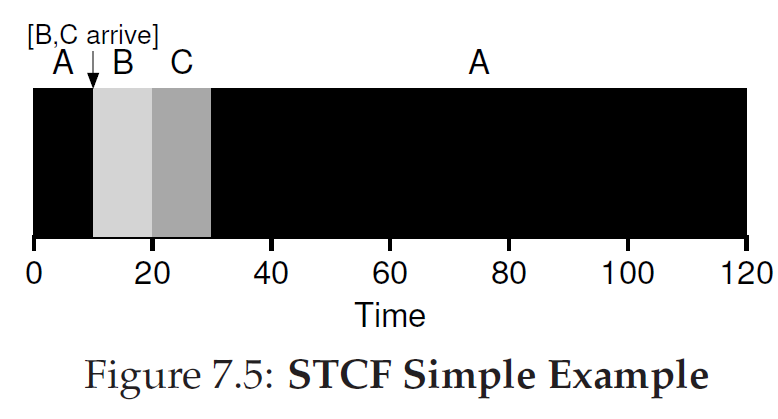
the scheduler can certainly do something else when B and C arrive: it can preempt job A and decide to run another job, perhaps continuing A later.
Round Robin (RR)
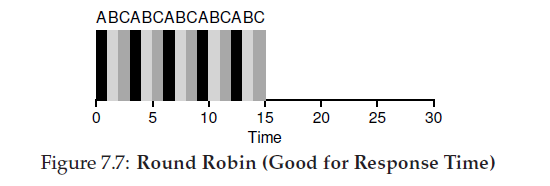
The basic idea of RR is simple: instead of running jobs to completion, RR runs a job for a time slice (sometimes called a scheduling quantum) and then switches to the next job in the run queue. It repeatedly does so until the jobs are finished.
the length of the time slice is critical for RR. The shorter it is, the better the performance of RR under the response-time metric. However, making the time slice too short is problematic: suddenly the cost of context switching will dominate overall performance.
Indeed, this is an inherent trade-off: if you are willing to be unfair, you can run shorter jobs to completion, but at the cost of response time; if you instead value fairness, response time is lowered, but at the cost of turnaround time.
Scheduling: The Multi-Level Feedback Queue (MLFQ)
Total Rules
• Rule 1: If Priority(A) > Priority(B), A runs (B doesn’t). • Rule 2: If Priority(A) = Priority(B), A & B run in RR. • Rule 3: When a job enters the system, it is placed at the highest priority (the topmost queue). • Rule 4: Once a job uses up its time allotment at a given level (regardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue). • Rule 5: After some time period S, move all the jobs in the system to the topmost queue.
How it words
MLFQ varies the priority of a job based on its observed behavior. If a job repeatedly relinquishes the CPU while waiting for input from the keyboard, MLFQ will keep its priority high, as this is how an interactive process might behave. If, instead, a job uses the CPU intensively for long periods of time,MLFQ will reduce its priority. In this way,MLFQ will try to learn about processes as they run, and thus use the history of the job to predict its future behavior.
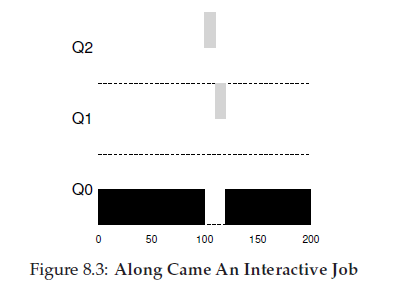
because it doesn’t know whether a job will be a short job or a long-running job, it first assumes itmight be a short job, thus giving the job high priority. If it actually is a short job, it will run quickly and complete; if it is not a short job, it will slowlymove down the queues, and thus soon prove itself to be a long-running more batch-like process. In this manner, MLFQ approximates SJF.
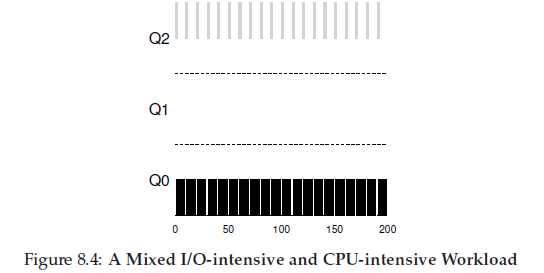
The MLFQ approach keeps B at the highest priority because B keeps releasing the CPU; if B is an interactive job,MLFQ further achieves its goal of running interactive jobs quickly.
We now have one more problem to solve: how to prevent gaming of our scheduler? The solution here is to perform better accounting of CPU time at each level of the MLFQ. Instead of forgetting how much of a time slice a process used at a given level, the scheduler should keep track; once a process has used its allotment, it is demoted to the next priority queue. Whether it uses the time slice in one long burst ormany small ones does notmatter.
We thus have the following rule: • Rule 3: Once a job uses up its time allotment at a given level (regardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue).
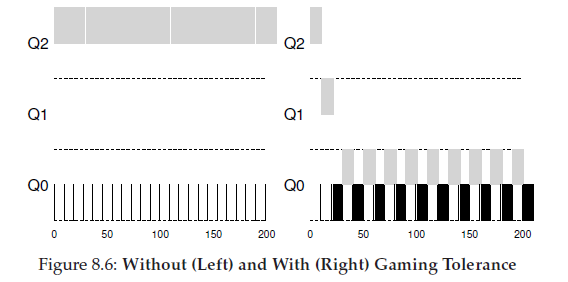
Real Life
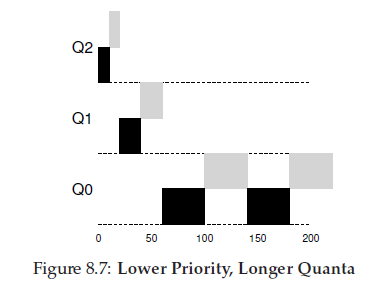
most MLFQ variants allow for varying time-slice length across different queues.
The high-priority queues are usually given short time slices; they are comprised of interactive jobs, after all, and thus quickly alternating between them makes sense (e.g., 10 or fewer milliseconds). The low-priority queues, in contrast, contain long-running jobs that are CPU-bound; hence, longer time slices work well (e.g., 100s of ms).
Scheduling: Proportional Share
Lottery scheduling also provides a number of mechanisms to manipulate tickets in different and sometimes useful ways.
One way is with the concept of ticket currency. Currency allows a user with a set of tickets to allocate tickets among their own jobs in whatever currency they would like; the system then automatically converts said currency into the correct global value.
Another useful mechanism is ticket transfer. With transfers, a process can temporarily hand off its tickets to another process. This ability is especially useful in a client/server setting, where a client process sends a message to a server asking it to do some work on the client’s behalf. To speed up the work, the client can pass the tickets to the server and thus try to maximize the performance of the server while the server is handling the client’s request. When finished, the server then transfers the tickets back to the client and all is as before.
Finally, ticket inflation can sometimes be a useful technique. With inflation, a process can temporarily raise or lower the number of tickets it owns. Of course, in a competitive scenario with processes that do not trust one another, this makes little sense; one greedy process could give itself a vast number of tickets and take over themachine. Rather, inflation can be applied in an environment where a group of processes trust one another; in such a case, if any one process knows it needsmore CPU time, it can boost its ticket value as a way to reflect that need to the system, all without communicating with any other processes.
Also, lottery scheduling has one nice property that stride scheduling does not: no global state. Imagine a new job enters in the middle of our stride scheduling example above; what should its pass value be? Should it be set to 0? If so, it will monopolize the CPU. With lottery scheduling, there is no global state per process; we simply add a new process with whatever tickets it has, update the single global variable to track how many total tickets we have, and go from there.
The Abstraction: Address Spaces
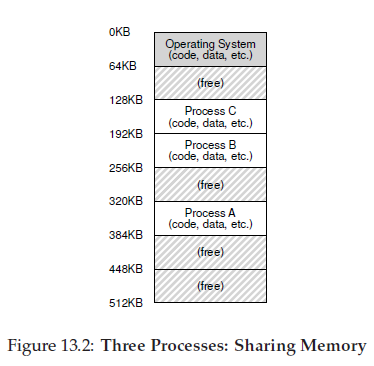
In the diagram, there are three processes (A, B, and C) and each of them have a small part of the 512KB physical memory carved out for them. Assuming a single CPU, the OS chooses to run one of the processes (say A), while the others (B and C) sit in the ready queue waiting to run.

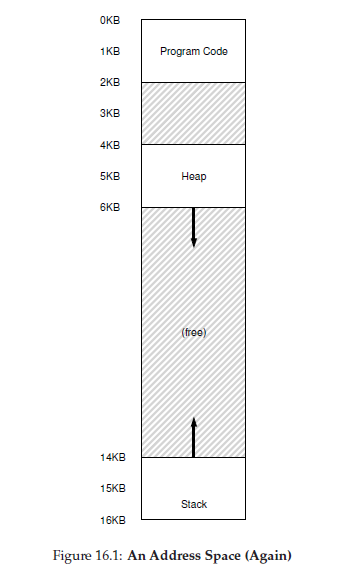
Next, we have the two regions of the address space that may grow (and shrink) while the program runs. Those are the heap (at the top) and the stack (at the bottom). We place them like this because each wishes to be able to grow, and by putting them at opposite ends of the address space, we can allow such growth: they just have to grow in opposite directions. The heap thus starts just after the code (at 1KB) and grows downward (say when a user requests more memory via malloc()); the stack starts at 16KB and grows upward (say when a user makes a procedure call).
Goals One major goal of a virtual memory (VM) system is transparency. The OS should implement virtual memory in a way that is invisible to the running program. Thus, the program shouldn’t be aware of the fact that memory is virtualized; rather, the program behaves as if it has its own private physical memory. Behind the scenes, the OS (and hardware) does all the work to multiplex memory among many different jobs, and hence implements the illusion.
Another goal of VM is efficiency. The OS should strive to make the virtualization as efficient as possible, both in terms of time (i.e., not making programs run much more slowly) and space (i.e., not using too much memory for structures needed to support virtualization). In implementing time-efficient virtualization, the OS will have to rely on hardware support, including hardware features such as TLBs (which we will learn about in due course).
Finally, a third VM goal is protection. The OS should make sure to protect processes from one another as well as the OS itself from processes. When one process performs a load, a store, or an instruction fetch, it should not be able to access or affect in any way the memory contents of any other process or the OS itself (that is, anything outside its address space). Protection thus enables us to deliver the property of isolation among processes; each process should be running in its own isolated cocoon, safe from the ravages of other faulty or even malicious processes.
Mechanism: Address Translation
LDE
In developing the virtualization of the CPU, we focused on a general mechanism known as limited direct execution (or LDE). The idea behind LDE is simple: for the most part, let the program run directly on the hardware; however, at certain key points in time (such as when a process issues a system call, or a timer interrupt occurs), arrange so that the OS gets involved and makes sure the “right” thing happens. Thus, the OS, with a little hardware support, tries its best to get out of the way of the running program, to deliver an efficient virtualization; however, by interposing at those critical points in time, the OS ensures that it maintains control over the hardware. Efficiency and control together are two of the main goals of any modern operating system.
Dynamic (Hardware-based) Relocation
Specifically, we’ll need two hardware registers within each CPU: one is called the base register, and the other the bounds (sometimes called a limit register). This base-and-bounds pair is going to allow us to place the address space anywhere we’d like in physical memory, and do so while ensuring that the process can only access its own address space.
when any memory reference is generated by the process, it is translated by the processor in the following manner:
physical address = virtual address + base
This is address translation:
the hardware takes a virtual address the process thinks it is referencing and transforms it into a physical address which is where the data actually resides.
What happened to that bounds (limit) register?
the bounds register is there to help with protection. Specifically, the processor will first check that the memory reference is within bounds to make sure it is legal.
Hardware Support: A Summary
First, as discussed in the chapter on CPU virtualization, we require two different CPU modes. The OS runs in privileged mode (or kernel mode), where it has access to the entire machine; applications run in user mode, where they are limited in what they can do. A single bit, perhaps stored in some kind of processor status word, indicates which mode the CPU is currently running in;
The hardware must also provide the base and bounds registers themselves; each CPU thus has an additional pair of registers, part of thememory management unit (MMU) of the CPU. When a user program is running, the hardware will translate each address, by adding the base value to the virtual address generated by the user program. The hardwaremust also be able to check whether the address is valid, which is accomplished by using the bounds register and some circuitry within the CPU.

Operating System Issues
So what the operating system do? There are few steps:
1.created
the OS must find space for its address space in memory. The OS will have to search a data structure (often called a free list) to find room for the new address space and then mark it used.
2.terminated
the OS must do some work when a process is terminated (i.e., when it exits gracefully, or is forcefully killed because it misbehaved), reclaiming all of its memory for use in other processes or the OS. the OS thus puts its memory back on the free list, and cleans up any associated data structures as need be.
3.context switch
The OS must save and restore the base-and-bounds pair when it switches between processes.
Specifically, when the OS decides to stop running a process, it must save the values of the base and bounds registers to memory, in some per-process structure such as the process structure or process control block (PCB). Similarly, when the OS resumes a running process (or runs it the first time), it must set the values of the base and bounds on the CPU to the correct values for this process.
To move a process’s address space, the OS first deschedules the process; then, the OS copies the address space from the current location to the new location; finally, the OS updates the saved base register (in the process structure) to point to the new location.
4.exception
The OS should be highly protective of the machine it is running, and thus it does not take kindly to a process trying to access memory or execute instructions that it shouldn’t.

16.Segmentation
If we do this, it will create lots of space unused
That why we need segementation
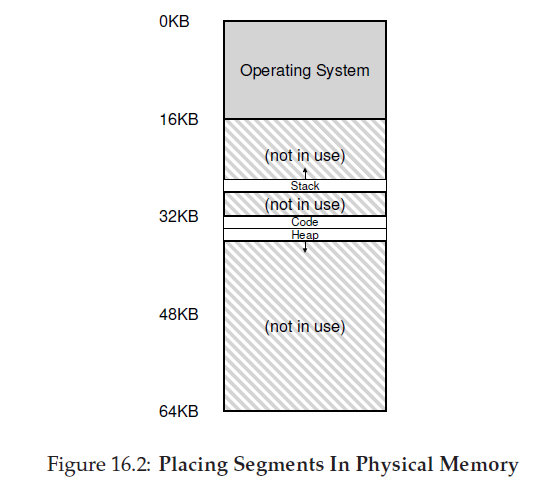
in the diagram, only used memory is allocated space in physical memory, and thus large address spaces with large amounts of unused address space (which we sometimes call sparse address spaces) can be accommodated.
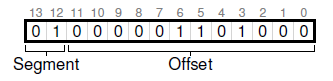
This is an explicit approach. Chop up the address space into segments based on the top few bits of the virtual address.

BY the code above we can translate the virtual address to physical address on memory.
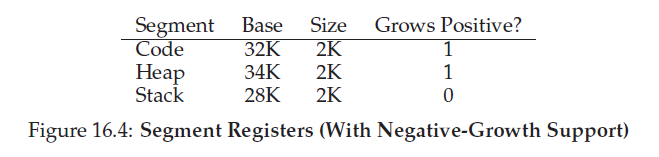
for the stack, the OS will recognize it and grow it reversly.
problems
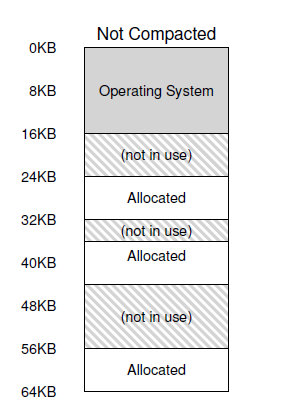
The general problem that arises is that physical memory quickly becomes full of little holes of free space, making it difficult to allocate new segments, or to grow existing ones. We call this problem external frag- mentation.
One solution to this problem would be to compact physical memory by rearranging the existing segments. For example, the OS could stop whichever processes are running, copy their data to one contiguous region of memory, change their segment register values to point to the new physical locations, and thus have a large free extent of memory with which to work. By doing so, the OS enables the new allocation request to succeed. However, compaction is expensive, as copying segments is memory-intensive and generally uses a fair amount of processor time.
A simpler approach is to use a free-list management algorithm that tries to keep large extents of memory available for allocation.
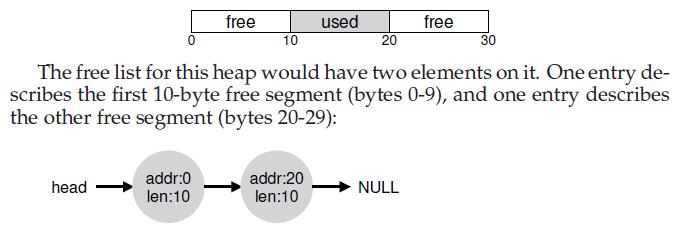
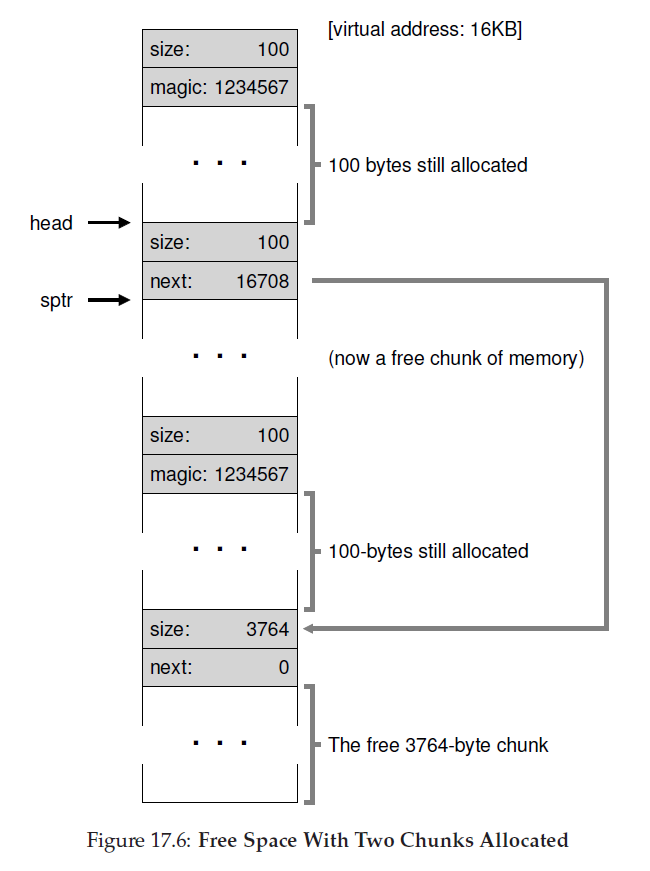
17.Free-Space Management
A free list contains a set of elements that describe the free space still remaining in the heap.
18.paging

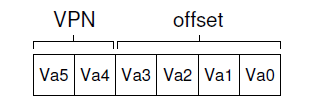
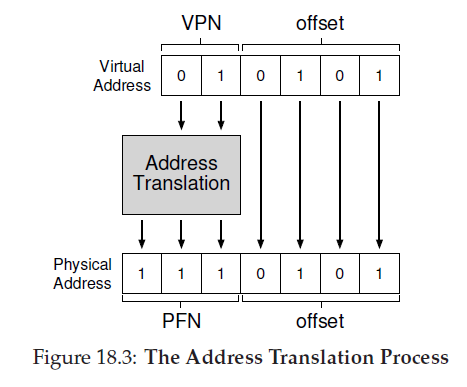
To record where each virtual page of the address space is placed in physical memory, the operating system usually keeps a per-process data structure known as a page table, The major role of the page table is to store address translations for each of the virtual pages of the address space, thus letting us know where in physical memory each page resides.
for example:
movl 21, %eax
Below is a PTE(page table entry)

what’s in the page table?
Any datastructure would work ,the simplest way is an array: The OS indexes the array by the virtual page number (VPN), and looks up the page-table entry (PTE) at that index in order to find the desired physical frame number (PFN).
19.Paging: Faster Translations (TLBs)
TLB
TLB:translation-lookaside buffer
A TLB, AKA address-translation cache, is part of the chip’s memory-management unit (MMU), and is simply a hardware cache of popular virtual-to-physical address translations.

The algorithm the hardware follows works like this: first, extract the virtual page number (VPN) from the virtual address (Line 1 in Figure 19.1), and check if the TLB holds the translation for this VPN (Line 2). If it does, we have a TLB hit, which means the TLB holds the translation. Success! We can now extract the page frame number (PFN) from the relevant TLB entry, concatenate that onto the offset from the original virtual address, and form the desired physical address (PA), and access memory (Lines 5–7), assuming protection checks do not fail (Line 4). If the CPU does not find the translation in the TLB (a TLB miss), we have some more work to do. In this example, the hardware accesses the page table to find the translation (Lines 11–12), and, assuming that the virtual memory reference generated by the process is valid and accessible (Lines 13, 15), updates the TLB with the translation (Line 18). These set of actions are costly, primarily because of the extra memory reference needed to access the page table (Line 12). Finally, once the TLB is updated, the hardware retries the instruction; this time, the translation is found in the TLB, and the memory reference is processed quickly.
Who Handles The TLB Miss
the hardware has to know exactly where the page tables are located in memory (via a page table base register, used in Line 11 in Figure 19.1), as well as their exact format; on a miss, the hardware would “walk” the page table, find the correct page-table entry and extract the desired translation, update the TLB with the translation, and retry the instruction.

what’s in TLB
VPN | PFN | other bits
The hardware searches the entries in parallel to see if there is a match.
More interesting are the “other bits”. For example, the TLB commonly has a valid bit, which says whether the entry has a valid translation or not. Also common are protection bits, which determine how a page can be accessed (as in the page table). For example, code pages might be marked read and execute, whereas heap pages might be marked read and write. There may also be a few other fields, including an address-space identifier, a dirty bit, and so forth; see below for more information.
A Real TLB Entry

We see a global bit (G), which is used for pages that are globally-shared among processes.
address space identifier (ASID). You can think of the ASID as a process identifier (PID), but usually it has fewer bits
a dirty bit which is marked when the page has been written to
a valid bit which tells the hardware if there is a valid translation present in the entry.
page mask field (not shown), which supports multiple page sizes
20.Paging: Smaller Tables
Page tables are way too big, we should do something about it.
Multi-level Page Tables
The page directory thus either can be used to tell you where a page of the page table is, or that the entire page of the page table contains no valid pages.
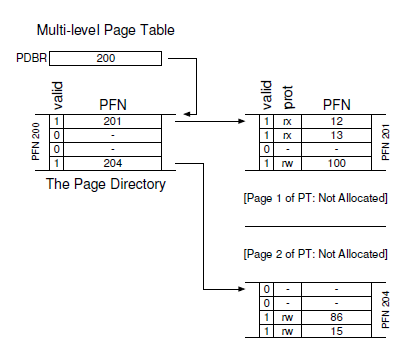
The page directory marks just two pages of the page table as valid (the first and last); thus, just those two pages of the page table reside in memory. And thus you can see one way to visualize what a multi-level table is doing: it just makes parts of the linear page table disappear (freeing those frames for other uses), and tracks which pages of the page table are allocated with the page directory.
The page directory, in a simple two-level table, contains one entry per page of the page table. It consists of a number of page directory entries (PDE). A PDE (minimally) has a valid bit and a page frame number (PFN), similar to a PTE.
this valid bit is slightly different: if the PDE entry is valid, it means that at least one of the pages of the page table that the entry points to (via the PFN) is valid, i.e., in at least one PTE on that page pointed to by this PDE, the valid bit in that PTE is set to one. If the PDE entry is not valid (i.e., equal to zero), the rest of the PDE is not defined.
A Detailed Multi-Level Example

To build a two-level page table for this address space, we start with our full linear page table and break it up into page-sized units. Recall our full table (in this example) has 256 entries; assume each PTE is 4 bytes in size. Thus, our page table is 1KB (256 × 4 bytes) in size. Given that we have 64-byte pages, the 1KB page table can be divided into 16 64-byte pages; each page can hold 16 PTEs. What we need to understand now is how to take a VPN and use it to index first into the page directory and then into the page of the page table. Remember that each is an array of entries; thus, all we need to figure out is how to construct the index for each from pieces of the VPN. Let’s first index into the page directory. Our page table in this example is small: 256 entries, spread across 16 pages. The page directory needs one entry per page of the page table; thus, it has 16 entries. As a result, we need four bits of the VPN to index into the directory; we use the top four bits of the VPN, as follows:

Once we extract the page-directory index (PDIndex for short) from the VPN, we can use it to find the address of the page-directory entry (PDE)with a simple calculation: PDEAddr = PageDirBase + (PDIndex
- sizeof(PDE)).
If the page-directory entry is marked invalid, we know that the access is invalid, and thus raise an exception. If, however, the PDE is valid,we have more work to do. Specifically, we now have to fetch the pagetable entry (PTE) from the page of the page table pointed to by this pagedirectory entry. To find this PTE, we have to index into the portion of the page table using the remaining bits of the VPN:
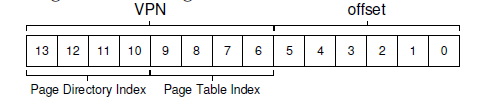
This page-table index (PTIndex for short) can then be used to index into the page table itself, giving us the address of our PTE: PTEAddr = (PDE.PFN « SHIFT) + (PTIndex * sizeof(PTE))
21.Beyond Physical Memory: Mechanisms
we generally refer to such space as swap space, because we swap pages out of memory to it and swap pages into memory from it.
To do so, the OS will need to remember the disk address of a given page.
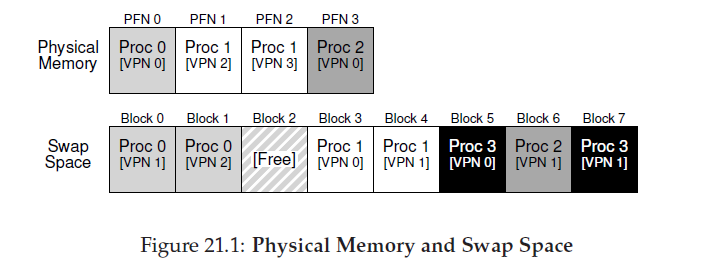
The Present Bit
If the VPN is not found in the TLB (i.e., a TLB miss), the hardware locates the page table in memory (using the page table base register) and looks up the page table entry (PTE) for this page using the VPN as an index. If the page is valid and present in physical memory, the hardware extracts the PFN from the PTE, installs it in the TLB, and retries the instruction, this time generating a TLB hit.
If the present bit is set to one, it means the page is present in physical memory and everything proceeds as above; if it is set to zero, the page is not in memory but rather on disk somewhere. The act of accessing a page that is not in physical memory is commonly referred to as a page fault.
Upon a page fault, theOS is invoked to service the page fault. A particular piece of code, known as a page-fault.
The Page Fault
If a page is not present and has been swapped to disk, the OS will need to swap the page into memory in order to service the page fault. Thus, a question arises: how will the OS know where to find the desired page? In many systems, the page table is a natural place to store such information.
When the OS receives a page fault for a page, it looks in the PTE to find the address, and issues the request to disk to fetch the page into memory.
Note that while the I/O is in flight, the process will be in the blocked state. Thus, the OS will be free to run other ready processes while the page fault is being serviced. Because I/O is expensive, this overlap of the I/O (page fault) of one process and the execution of another is yet another way a multiprogrammed system can make the most effective use of its hardware.
Page Fault Control Flow

From the hardware control flow diagram in Figure 21.2, notice that there are now three important cases to understand when a TLB miss occurs.
First, that the page was both present and valid (Lines 18–21); in this case, the TLB miss handler can simply grab the PFN from the PTE, retry the instruction (this time resulting in a TLB hit), and thus continue as described (many times) before.
In the second case (Lines 22–23), the page fault handler must be run; although this was a legitimate page for the process to access (it is valid, after all), it is not present in physical memory.
Third (and finally), the access could be to an invalid page, due for example to a bug in the program (Lines 13–14). In this case, no other bits in the PTE really matter; the hardware traps this invalid access, and the OS trap handler runs, likely terminating the offending proces.

From the software control flow in Figure 21.3, we can see what the OS roughly must do in order to service the page fault.
First, the OS must find a physical frame for the soon-to-be-faulted-in page to reside within; if there is no such page, we’ll have to wait for the replacement algorithm to run and kick some pages out of memory, thus freeing them for use here.
With a physical frame in hand, the handler then issues the I/O request to read in the page from swap space. Finally, when that slow operation completes, the OS updates the page table and retries the instruction.
The retry will result in a TLB miss, and then, upon another retry, a TLB hit, at which point the hardware will be able to access the desired item.
replacement
To keep a small amount of memory free, most operating systems thus have some kind of high watermark (HW) and low watermark (LW) to help decidewhen to start evicting pages frommemory.
when the OS notices that there are fewer than LW pages available, a background thread that is responsible for freeing memory runs. The thread evicts pages until there are HW pages available. The background thread, sometimes called the swap daemon or page daemon1, then goes to sleep, happy that it has freed some memory for running processes and the OS to use.
22.Beyond Physical Memory: Policies
The Optimal Replacement Policy
We just assume the optimal replacement policy leads to the fewest number of misses overall.
replacing the page that will be accessed furthest in the future is the optimal policy, resulting in the fewest-possible cache misses.
However it’s only the prefect siyuation and cannot be acchived by real computers, it’s more like a standerd to exam how prefect the mechanism or algorithm are.
Using History: LRU
Besides FIFO(First In First Out) and Random, the LRU(Least-Recently-Used) is a better mechnism.
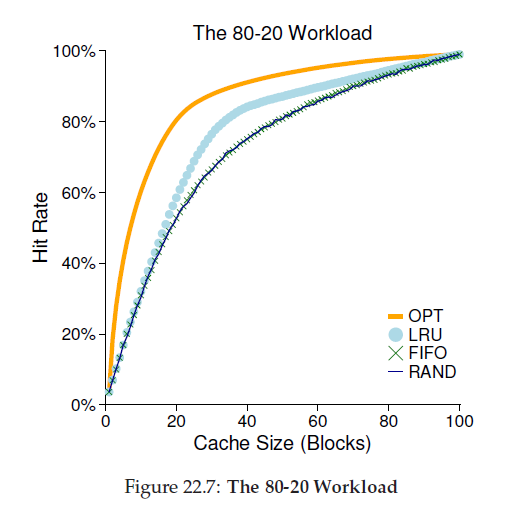
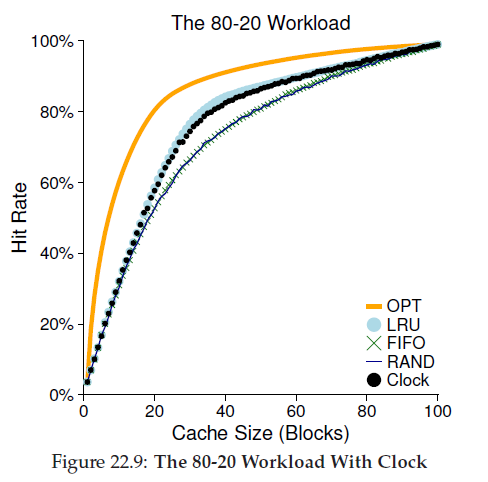
The examine above is called the “80-20” workload, which exhibits locality: 80% of the references are made to 20% of the pages (the “hot” pages); the remaining 20% of the references are made to the remaining 80% of the pages (the “cold” pages).
As you can see from the figure, while both random and FIFO do reasonably well, LRU does better, as it is more likely to hold onto the hot pages; as those pages have been referred to frequently in the past, they are likely to be referred to again in the near future. Optimal once again does better, showing that LRU’s historical information is not perfect.
Implementing Historical Algorithms
In order to find the least recently used page, we can, obviously, set up an array and each time we evict, we just search through the array and find the least recently used page. But the cost is too huge even for modern computer.
Approximating LRU is more feasible from a computational-overhead standpoint. The idea requires some hardware support, in the form of a use bit (sometimes called the reference bit), the first of which was implemented in the first system with paging.
Take clock algorithm for example:
when a replacement must occur, the OS checks if the currently-pointed to page P has a use bit of 1 or 0. If 1, this implies that page P was recently used and thus is not a good candidate for replacement. Thus, the use bit for P set to 0 (cleared), and the clock hand is incremented to the next page (P + 1).
We can also consider dirty page, The reason for this: if a page has been modified and is thus dirty, it must be written back to disk to evict it, which is expensive. If it has not been modified (and is thus clean), the eviction is free; the physical frame can simply be reused for other purposes without additional I/O. Thus, some VM systems prefer to evict clean pages over dirty pages.
As for the dirty pages which refers to the pages that have been modified and need to be writed back to disk,many systems collect a number of pending writes together in memory and write them to disk in one (more efficient) write. This behavior is usually called clustering or simply grouping of writes, and is effective because of the nature of disk drives, which perform a single large write more efficiently than many small ones.
The Real Life
This chapter introduce a real Operating System:
The VAX/VMS Virtual Memory System
Memory Management Hardware
Reduce Pressure
The system reduced the pressure page tables place on memory in two ways.
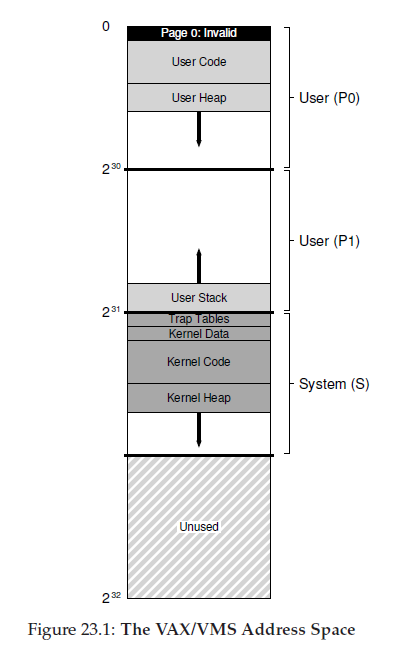
First, by segmenting the user address space into two, the VAX-11 provides a page table for each of these regions (P0 and P1) per process; thus, no page-table space is needed for the unused portion of the address space between the stack and the heap. The base and bounds registers are used as you would expect; a base register holds the address of the page table for that segment, and the bounds holds its size (i.e., number of page-table entries).
Second, the OS reduces memory pressure even further by placing user page tables (for P0 and P1, thus two per process) in kernel virtual memory. Thus, when allocating or growing a page table, the kernel allocates space out of its own virtual memory, in segment S. If memory comes under severe pressure, the kernel can swap pages of these page tables out to disk, thus making physical memory available for other uses.
Putting page tables in kernel virtualmemorymeans that address translation is even further complicated.
For example, to translate a virtual address in P0 or P1, the hardware has to first try to look up the page-table entry for that page in its page table (the P0 or P1 page table for that process); in doing so, however, the hardware may first have to consult the system page table (which lives in physical memory); with that translation complete, the hardware can learn the address of the page of the page table, and then finally learn the address of the desired memory access. All of this, fortunately, is made faster by the VAX’s hardware-managed TLBs, which usually (hopefully) circumvent this laborious lookup.
Null Pointer Exception
Also,the code segment never begins at page 0. This page, instead, is marked inaccessible, in order to provide some support for detecting null-pointer accesses. Thus, one concern when designing an address space is support for debugging, which the inaccessible zero page provides here in some form.
Kernel Everywhere
the kernel virtual address space (i.e., its data structures and code) is a part of each user address space.
On a context switch, the OS changes the P0 and P1 registers to point to the appropriate page tables of the soon-to-be-run process; however, it does not change the S base and bound registers, and as a result the “same” kernel structures are mapped into each user address space.
The OS is naturally written and compiled, without worry of where the data it is accessing comes from. If in contrast the kernel were located entirely in physical memory, it would be quite hard to do things like swap pages of the page table to disk; if the kernel were given its own address space, moving data between user applications and the kernel would again be complicated and painful. With this construction (now used widely), the kernel appears almost as a library to applications, albeit a protected one.
Page Replacement
Secondchance Lists
VMS introduced two secondchance lists where pages are placed before getting evicted from memory, specifically a global clean-page free list and dirty-page list.
When a process P exceeds its limit, a page is removed from its per-process FIFO; if clean (not modified), it is placed on the end of the clean-page list; if dirty (modified), it is placed on the end of the dirty-page list.
If another process Q needs a free page, it takes the first free page off of the global clean list. However, if the original process P faults on that page before it is reclaimed, P reclaims it from the free (or dirty) list, thus avoiding a costly disk access. The bigger these global second-chance lists are, the closer the segmented FIFO algorithm performs to LRU.
Page Clustering
Because disks do better with large transfers, VMS adds a number of optimizations, but most important is clustering.
With clustering, VMS groups large batches of pages together from the global dirty list, and writes them to disk in one fell swoop (thus making them clean).
Demand Zeroing
With demand zeroing, the OS instead does very little work when the page is added to your address space; it puts an entry in the page table that marks the page inaccessible. If the process then reads or writes the page, a trap into the OS takes place. When handling the trap, the OS notices (usually through some bits marked in the “reserved for OS” portion of the page table entry) that this is actually a demand-zero page; at this point, the OS then does the needed work of finding a physical page, zeroing it, and mapping it into the process’s address space. If the process never accesses the page, all of this work is avoided, and thus the virtue of demand zeroing.
copy-on-write(COW)
when the OS needs to copy a page from one address space to another, instead of copying it, it can map it into the target address space and mark it readonly in both address spaces.
If one of the address spaces does indeed try to write to the page, it will trap into the OS. The OS will then notice that the page is a COWpage, and thus (lazily) allocate a new page, fill it with the data, and map this new page into the address space of the faulting process.
Concurrency
26.Concurrency: An Introduction
A multi-threaded programhasmore than one point of execution (i.e., multiple PCs, each of which is being fetched and executed from). Perhaps another way to think of this is that each thread is very much like a separate process, except for one difference: they share the same address space and thus can access the same data.
The state of a single thread is thus very similar to that of a process. It has a program counter (PC) that tracks where the program is fetching instructions from. Each thread has its own private set of registers it uses for computation; thus, if there are two threads that are running on a single processor, when switching from running one (T1) to running the other (T2), a context switch must take place. The context switch between threads is quite similar to the context switch between processes, as the register state of T1 must be saved and the register state of T2 restored before running T2.
With processes, we saved state to a process control block (PCB); now, we’ll need one or more thread control blocks (TCBs) to store the state of each thread of a process. There is one major difference, though, in the context switch we perform between threads as compared to processes: the address space remains the same (i.e., there is no need to switch which page table we are using).
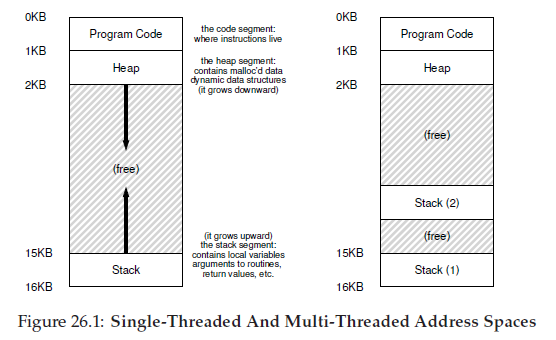
Second, instead of a single stack in the address space, there will be one per thread. Let’s say we have a multi-threaded process that has two threads in it; the resulting address space looks different.
In this figure, you can see two stacks spread throughout the address
space of the process. Thus, any stack-allocated variables, parameters, return
values, and other things that we put on the stack will be placed in
what is sometimes called thread-local storage, i.e., the stack of the relevant
thread.
Thread Creation
Once a thread is created, it may start running right away (depending on the whims of the scheduler); alternately, itmay be put in a “ready” but not “running” state and thus not run yet.
one way to think about thread creation is that it is a bit like making a function call; however, instead of first executing the function and then returning to the caller, the system instead creates a new thread of execution for the routine that is being called, and it runs independently of the caller, perhaps before returning from the create, but perhaps much later. What runs next is determined by the OS scheduler,it is hard to know what will run at any given moment in time.
Sharing Data and Uncontrolled Scheduling

Whatwe have demonstrated here is called a race condition: the results depend on the timing execution of the code. With some bad luck (i.e., context switches that occur at untimely points in the execution), we get the wrong result. In fact, we may get a different result each time; thus, instead of a nice deterministic computation (which we are used to from computers), we call this result indeterminate, where it is not knownwhat the output will be and it is indeed likely to be different across runs.
What we really want for this code is what we call mutual exclusion. This property guarantees that if one thread is executing within the critical section, the others will be prevented from doing so.
Atomicity
Atomically, in this context, means “as a unit”, which sometimes we take as “all or none.” What we’d like is to execute the three instruction sequence atomically:
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c
Thus, what we will instead do is ask the hardware for a few useful instructions upon which we can build a general set of what we call synchronization primitives. By using these hardware synchronization primitives, in combination with some help from the operating system, we will be able to build multi-threaded code that accesses critical sections in a synchronized and controlled manner, and thus reliably produces the correct result despite the challenging nature of concurrent execution.
KEY CONCURRENCY TERMS
Critical section
a piece of code that accesses a shared resource, usually a variable or data structure.
Race condition
arises if multiple threads of execution enter the critical section at roughly the same time; both attempt to update the shared data structure, leading to a surprising (and perhaps undesirable) outcome.
Indeterminate program
consists of one or more race conditions; the output of the program varies from run to run, depending on which threads ran when. The outcome is thus not deterministic, something we usually expect from computer systems.
Mutual Exclusion
To avoid these problems, threads should use some kind of mutual exclusion primitives; doing so guarantees that only a single thread ever enters a critical section, thus avoiding races, and resulting in deterministic program outputs.