- 2020-02-05
- 2020-02-09
- 2020-02-13
- 2020-02-16
- 2020-02-17
- 2020-02-18
- 2020-02-19
- 2020-02-22
- 2020-02-23
- 2020-02-24
- 2020-02-25
- 2020-02-26
- 2020-02-27
2020-02-05
588. Design In-Memory File System
Description
Design an in-memory file system to simulate the following functions:
ls: Given a path in string format. If it is a file path, return a list that only contains this file’s name. If it is a directory path, return the list of file and directory names in this directory. Your output (file and directory names together) should in lexicographic order.
mkdir: Given a directory path that does not exist, you should make a new directory according to the path. If the middle directories in the path don’t exist either, you should create them as well. This function has void return type.
addContentToFile: Given a file path and file content in string format. If the file doesn’t exist, you need to create that file containing given content. If the file already exists, you need to append given content to original content. This function has void return type.
readContentFromFile: Given a file path, return its content in string format.
Example:
Input: [“FileSystem”,”ls”,”mkdir”,”addContentToFile”,”ls”,”readContentFromFile”] [[],[”/”],[“/a/b/c”],[“/a/b/c/d”,”hello”],[”/”],[“/a/b/c/d”]]
Output: [null,[],null,null,[“a”],”hello”]
Explanation: filesystem
Note:
You can assume all file or directory paths are absolute paths which begin with / and do not end with / except that the path is just “/”. You can assume that all operations will be passed valid parameters and users will not attempt to retrieve file content or list a directory or file that does not exist. You can assume that all directory names and file names only contain lower-case letters, and same names won’t exist in the same directory.
Solution
class FileSystem {
class node{
boolean isFile = false;
Map<String, node> children = new HashMap();
String content = "";
String name="";
}
node root = null;
public FileSystem() {
root = new node();
}
public List<String> ls(String path) {
node cur = root;
List<String> res = new ArrayList();
for(String child: path.split("/")){
if(child.isEmpty()) continue;
node next = cur.children.get(child);
if(next == null) return res;
cur = next;
}
if(cur.isFile){
res.add(cur.name);
return res;
}
for(String dirName : cur.children.keySet()){
res.add(dirName);
}
Collections.sort(res);
return res;
}
public void mkdir(String path) {
String[] paths = path.split("/");
node cur = root;
for(String p:paths){
if(p.isEmpty()) continue;
node next = cur.children.get(p);
if(next == null){
next = new node();
next.name = p;
cur.children.put(p,next);
}
cur = next;
}
}
public void addContentToFile(String filePath, String content) {
String[] paths = filePath.split("/");
node cur = root;
for(String p:paths){
if(p.isEmpty()) continue;
node next = cur.children.get(p);
if(next == null){
next = new node();
next.name = p;
cur.children.put(p,next);
}
cur = next;
}
cur.isFile = true;
cur.content += content;
}
public String readContentFromFile(String filePath) {
String[] paths = filePath.split("/");
node cur = root;
for(String p:paths){
if(p.isEmpty()) continue;
node next = cur.children.get(p);
if(next == null){
return "";
}
cur = next;
}
return cur.content;
}
}
/**
* Your FileSystem object will be instantiated and called as such:
* FileSystem obj = new FileSystem();
* List<String> param_1 = obj.ls(path);
* obj.mkdir(path);
* obj.addContentToFile(filePath,content);
* String param_4 = obj.readContentFromFile(filePath);
*/
472. Concatenated Words
Description
Given a list of words (without duplicates), please write a program that returns all concatenated words in the given list of words. A concatenated word is defined as a string that is comprised entirely of at least two shorter words in the given array.
Example: Input: [“cat”,”cats”,”catsdogcats”,”dog”,”dogcatsdog”,”hippopotamuses”,”rat”,”ratcatdogcat”]
Output: [“catsdogcats”,”dogcatsdog”,”ratcatdogcat”]
Explanation: “catsdogcats” can be concatenated by “cats”, “dog” and “cats”; “dogcatsdog” can be concatenated by “dog”, “cats” and “dog”; “ratcatdogcat” can be concatenated by “rat”, “cat”, “dog” and “cat”. Note: The number of elements of the given array will not exceed 10,000 The length sum of elements in the given array will not exceed 600,000. All the input string will only include lower case letters. The returned elements order does not matter.
Solution
class Solution {
//sort by length first, so will start with the shortest word.
//cause words can only consist with shorter words.
public List<String> findAllConcatenatedWordsInADict(String[] words) {
List<String> res = new ArrayList();
HashSet<String> dict = new HashSet<>();
Arrays.sort(words,(a,b)->(a.length()-b.length()));
for(int i = 0; i<words.length;i++){
if(canConcate(words[i],dict)){
res.add(words[i]);
}
//only add the word to dict afterward, so only contains words smaller than itself.
dict.add(words[i]);
}
return res;
}
private boolean canConcate(String word, HashSet<String> dict){
if(dict.isEmpty()) return false;
int len = word.length();
boolean[] dp = new boolean[len+1];
dp[0] = true;
for(int i = 1;i<=len;i++){
for(int j = 0; j<i;j++){
//if the previous is not able to be concated, skip.
if(!dp[j]){
continue;
}
String temp = word.substring(j,i);
if(dict.contains(temp)){
//set to true and continue to next position.
dp[i] = true;
break;
}
}
}
return dp[len];
}
}
1268. Search Suggestions System
Description
Given an array of strings products and a string searchWord. We want to design a system that suggests at most three product names from products after each character of searchWord is typed. Suggested products should have common prefix with the searchWord. If there are more than three products with a common prefix return the three lexicographically minimums products.
Return list of lists of the suggested products after each character of searchWord is typed.
Example 1:
Input: products = [“mobile”,”mouse”,”moneypot”,”monitor”,”mousepad”], searchWord = “mouse” Output: [ [“mobile”,”moneypot”,”monitor”], [“mobile”,”moneypot”,”monitor”], [“mouse”,”mousepad”], [“mouse”,”mousepad”], [“mouse”,”mousepad”] ] Explanation: products sorted lexicographically = [“mobile”,”moneypot”,”monitor”,”mouse”,”mousepad”] After typing m and mo all products match and we show user [“mobile”,”moneypot”,”monitor”] After typing mou, mous and mouse the system suggests [“mouse”,”mousepad”] Example 2:
Input: products = [“havana”], searchWord = “havana” Output: [[“havana”],[“havana”],[“havana”],[“havana”],[“havana”],[“havana”]] Example 3:
Input: products = [“bags”,”baggage”,”banner”,”box”,”cloths”], searchWord = “bags” Output: [[“baggage”,”bags”,”banner”],[“baggage”,”bags”,”banner”],[“baggage”,”bags”],[“bags”]] Example 4:
Input: products = [“havana”], searchWord = “tatiana” Output: [[],[],[],[],[],[],[]]
Constraints:
1 <= products.length <= 1000 There are no repeated elements in products. 1 <= Σ products[i].length <= 2 * 10^4 All characters of products[i] are lower-case English letters. 1 <= searchWord.length <= 1000 All characters of searchWord are lower-case English letters.
Solution
Intuition
In a sorted list of words, for any word A[i], all its sugested words must following this word in the list.
For example, if A[i] is a prefix of A[j], A[i] must be the prefix of A[i + 1], A[i + 2], …, A[j]
Explanation
With this observation, we can binary search the position of each prefix of search word, and check if the next 3 words is a valid suggestion.
Complexity
Time O(NlogN) for sorting Space O(logN) for quick sort.
Time O(logN) for each query Space O(query) for each query where I take word operation as O(1)
class Solution {
public List<List<String>> suggestedProducts(String[] products, String searchWord) {
Arrays.sort(products);
String key = "";
List<List<String>> res = new ArrayList();
for(char c: searchWord.toCharArray()){
key += c;
int idx = Arrays.binarySearch(products, key);
if(idx<0){
idx = -idx - 1;
}
res.add(checkValidation(key, products, idx));
}
return res;
}
private List<String> checkValidation(String searchWord, String[] words, int idx){
List<String> res = new ArrayList();
int len = searchWord.length();
for(int i = idx; i<words.length && i < idx+3; i++){
String word = words[i];
if(word.length() >= len && searchWord.equals(word.substring(0,len))){
res.add(word);
}else{
break;
}
}
return res;
}
}
#2020-02-06
1044. Longest Duplicate Substring
Description
Given a string S, consider all duplicated substrings: (contiguous) substrings of S that occur 2 or more times. (The occurrences may overlap.)
Return any duplicated substring that has the longest possible length. (If S does not have a duplicated substring, the answer is “”.)
Example 1:
Input: “banana” Output: “ana” Example 2:
Input: “abcd” Output: “”
Note:
2 <= S.length <= 10^5 S consists of lowercase English letters.
Solution
class Solution {
//use binary search to find the largest lenth of the string.
public String longestDupSubstring(String S) {
int lo = 1;
int hi = S.length()-1;
int idx = -1;
while(lo<=hi){
int mid = lo+(hi-lo)/2;
int startIndex = find(S,mid);
if(startIndex==-1){
hi = mid-1;
}
else{
idx = startIndex;
lo = mid+1;
}
}
return idx==-1? "" : S.substring(idx,idx+hi);
}
//if use hashmap, memory will exceed for extra long string, use hash further.
public int find(String S, int len){
if(len == 0) return -1;
HashSet<String> seen = new HashSet();
for(int i = 0;i<=S.length()-len;i++){
String temp = S.substring(i,i+len);
if(seen.contains(temp)) return i;
seen.add(temp);
}
return -1;
}
}
694. Number of Distinct Islands
Description
Given a non-empty 2D array grid of 0’s and 1’s, an island is a group of 1’s (representing land) connected 4-directionally (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
Count the number of distinct islands. An island is considered to be the same as another if and only if one island can be translated (and not rotated or reflected) to equal the other.
Example 1: 11000 11000 00011 00011 Given the above grid map, return 1. Example 2: 11011 10000 00001 11011 Given the above grid map, return 3.
Notice that: 11 1 and 1 11 are considered different island shapes, because we do not consider reflection / rotation. Note: The length of each dimension in the given grid does not exceed 50.
Solution
//use a char to record the movement to destroy an island from left up corner.
//use trversal to make sure start from the left up corner.
//use int[][] dirs to make sure the order of the direction it will try to use.
class Solution {
int[][] dirs = new int[][][[0,-1],[0,1],[1,0],[-1,0]];
char[] dir_char = new char[]{'u','d','r','l'};
public int numDistinctIslands(int[][] grid) {
if(grid == null || grid.length == 0 || grid[0].length ==0) return 0;
HashSet<String> seen = new HashSet();
int count = 0;
for(int i = 0;i<grid.length;i++){
for(int j = 0;j<grid[0].length;j++){
if(grid[i][j]==1){
StringBuilder sb = new StringBuilder();
search(grid, 's', j,i,sb);
String path = sb.toString();
if(!seen.contains(path)) {
count++;
seen.add(path);
}
}
}
}
return count;
}
private void search(int[][] grid, char d, int x, int y , StringBuilder sb ){
grid[y][x] = 0;
sb.append(d);
for(int i = 0;i<4;i++){
int newx = x + dirs[i][0];
int newy = y + dirs[i][1];
if(newx < 0 || newy<0 || newy>=grid.length || newx >= grid[y].length || grid[newy][newx]!=1 ) continue;
search(grid, dir_char[i], newx, newy, sb);
//why adding a back step?
//[1,1,0]
//[0,1,1]
//[0,0,0]
//[1,1,1]
//[0,1,0]
//both path are srdr.
//with b: srdrbbb & srdbrbb
sb.append('b');
}
}
}
1167. Minimum Cost to Connect Sticks
Description
You have some sticks with positive integer lengths.
You can connect any two sticks of lengths X and Y into one stick by paying a cost of X + Y. You perform this action until there is one stick remaining.
Return the minimum cost of connecting all the given sticks into one stick in this way.
Example 1:
Input: sticks = [2,4,3] Output: 14 Example 2:
Input: sticks = [1,8,3,5] Output: 30
Constraints:
1 <= sticks.length <= 10^4 1 <= sticks[i] <= 10^4
Solution
//always pick the shortest, casue the earlier the etick participate in the joining, the more duplication it will be.
class Solution {
public int connectSticks(int[] sticks) {
if(sticks == null || sticks.length==0) return 0;
PriorityQueue<Integer> pq = new PriorityQueue(sticks.length);
for(int num: sticks){
pq.offer(num);
}
int count = 0;
while(pq.size()>1){
int cost = pq.poll() + pq.poll();
count+=cost;
pq.offer(cost);
}
return count;
}
}
2020-02-09
1000. Minimum Cost to Merge Stones
Description
There are N piles of stones arranged in a row. The i-th pile has stones[i] stones.
A move consists of merging exactly K consecutive piles into one pile, and the cost of this move is equal to the total number of stones in these K piles.
Find the minimum cost to merge all piles of stones into one pile. If it is impossible, return -1.
Example 1:
Input: stones = [3,2,4,1], K = 2 Output: 20 Explanation: We start with [3, 2, 4, 1]. We merge [3, 2] for a cost of 5, and we are left with [5, 4, 1]. We merge [4, 1] for a cost of 5, and we are left with [5, 5]. We merge [5, 5] for a cost of 10, and we are left with [10]. The total cost was 20, and this is the minimum possible. Example 2:
Input: stones = [3,2,4,1], K = 3 Output: -1 Explanation: After any merge operation, there are 2 piles left, and we can’t merge anymore. So the task is impossible. Example 3:
Input: stones = [3,5,1,2,6], K = 3 Output: 25 Explanation: We start with [3, 5, 1, 2, 6]. We merge [5, 1, 2] for a cost of 8, and we are left with [3, 8, 6]. We merge [3, 8, 6] for a cost of 17, and we are left with [17]. The total cost was 25, and this is the minimum possible.
Note:
1 <= stones.length <= 30 2 <= K <= 30 1 <= stones[i] <= 100
Solution
class Solution {
public static int mergeStones(int[] stones, int K) {
if (stones == null || stones.length == 0 || (stones.length - 1) % (K - 1) != 0) {
return -1;
}
int len = stones.length;
int[] prefix = new int[len + 1];
//prefix to count sum between i & j.
for (int i = 0; i < len; i++) {
prefix[i + 1] = prefix[i] + stones[i];
}
int[][] dp = new int[len][len];
//base case.
for (int i = 0; i <= len - K; i++) {
dp[i][i + K - 1] = prefix[i + K] - prefix[i];
}
//m is the interval.
for (int m = K+1; m <= len; m++) {
//start from 0 to tail.
for(int i = 0; i+m <=len;i++ ){
int j = i+m-1;
dp[i][j] = Integer.MAX_VALUE;
//must jump K-1 so i->i+mid is always valid, otherwise will always getting 0 cause the min.
for(int mid = i; mid <j;mid+=K-1){
dp[i][j] = Math.min(dp[i][mid]+dp[mid+1][j], dp[i][j]);
}
if((j-i)%(K-1)==0){
//need to add the sum, cause no matter how to group inside i->j, the count is always sum[i,j], plus the cost to group i->mid and mid+1->j.
dp[i][j] += prefix[j+1] - prefix[i];
}
}
}
return dp[0][len-1];
}
}
866. Prime Palindrome
Description
Find the smallest prime palindrome greater than or equal to N.
Recall that a number is prime if it’s only divisors are 1 and itself, and it is greater than 1.
For example, 2,3,5,7,11 and 13 are primes.
Recall that a number is a palindrome if it reads the same from left to right as it does from right to left.
For example, 12321 is a palindrome.
Example 1:
Input: 6 Output: 7 Example 2:
Input: 8 Output: 11 Example 3:
Input: 13 Output: 101
Note:
1 <= N <= 10^8 The answer is guaranteed to exist and be less than 2 * 10^8.
Solution
Intuition Write some example, you find all even length palindromes are divisible by 11. So we need to search only palindrome with odd length.
We can prove as follow: 11 % 11 = 0 1111 % 11 = 0 111111 % 11 = 0 11111111 % 11 = 0
So: 1001 % 11 = (1111 - 11 * 10) % 11 = 0 100001 % 11 = (111111 - 1111 * 10) % 11 = 0 10000001 % 11 = (11111111 - 111111 * 10) % 11 = 0
For any palindrome with even length: abcddcba % 11 = (a * 10000001 + b * 100001 * 10 + c * 1001 * 100 + d * 11 * 1000) % 11 = 0
All palindrome with even length is multiple of 11. So among them, 11 is the only one prime if (8 <= N <= 11) return 11
For other cases, we consider only palindrome with odd dights.
More Generally Explanation from @chuan-chih: A number is divisible by 11 if sum(even digits) - sum(odd digits) is divisible by 11. Base case: 0 Inductive step: If there is no carry when we add 11 to a number, both sums +1. Whenever carry happens, one sum -10 and the other +1. The invariant holds in both cases.
Time Complexity O(10000) to check all numbers 1 - 10000. isPrime function is O(sqrt(x)) in worst case. But only sqrt(N) worst cases for 1 <= x <= N In general it’s O(logx)
class Solution {
public int primePalindrome(int N) {
if(N>=8 && N<=11) return 11;
for(int x = 1; x<=100000;x++){
String s = String.valueOf(x);
String r = new StringBuilder(s).reverse().toString();
int y = Integer.parseInt(s+r.substring(1));
if(y>=N && isPrime(y)) return y;
}
return -1;
}
private boolean isPrime(int N){
if(N < 2 || N % 2 == 0) return N==2;
for(int i = 3;i*i<=N;i+=2){
if(N%i==0) return false;
}
return true;
}
}
1102. Path With Maximum Minimum Value
Description
Given a matrix of integers A with R rows and C columns, find the maximum score of a path starting at [0,0] and ending at [R-1,C-1].
The score of a path is the minimum value in that path. For example, the value of the path 8 → 4 → 5 → 9 is 4.
A path moves some number of times from one visited cell to any neighbouring unvisited cell in one of the 4 cardinal directions (north, east, west, south).
Example 1:
Input: [[5,4,5],[1,2,6],[7,4,6]] Output: 4 Explanation: The path with the maximum score is highlighted in yellow. Example 2:
Input: [[2,2,1,2,2,2],[1,2,2,2,1,2]] Output: 2 Example 3:
Input: [[3,4,6,3,4],[0,2,1,1,7],[8,8,3,2,7],[3,2,4,9,8],[4,1,2,0,0],[4,6,5,4,3]] Output: 3
Note:
1 <= R, C <= 100 0 <= A[i][j] <= 10^9
Solution
even though the pq might include some node not int e final path, the min will always be in the path. Cause you always choose the larger one, so the node outside the path is still larger than the one in the node, so it will not effect the min inside the path.
class Solution {
class cell{
int row, col, val;
cell(int row, int col, int val){
this.row = row;
this.col = col;
this.val = val;
}
}
static int[][] moves = new int[][] [[-1, 0], [1, 0], [0, 1], [0, -1]];
public int maximumMinimumPath(int[][] A) {
PriorityQueue<cell> q = new PriorityQueue<>((a,b)->b.val-a.val);
q.add(new cell(0,0,A[0][0]));
boolean[][] visited = new boolean[A.length][A[0].length];
visited[0][0] = true;
int min = A[0][0];
while(!q.isEmpty()){
cell cur = q.poll();
if(cur.val<min) min = cur.val;
if(cur.row == A.length-1&& cur.col == A[0].length-1) return min;
for(int[] dir : moves){
int newr = cur.row + dir[0];
int newc = cur.col + dir[1];
if(newr>= 0 && newr < A.length && newc >=0 && newc < A[0].length && !visited[newr][newc]){
q.add(new cell(newr, newc, A[newr][newc]));
visited[newr][newc] = true;
}
}
}
return -1;
}
}
1099. Two Sum Less Than K
Description
Given an array A of integers and integer K, return the maximum S such that there exists i < j with A[i] + A[j] = S and S < K. If no i, j exist satisfying this equation, return -1.
Example 1:
Input: A = [34,23,1,24,75,33,54,8], K = 60 Output: 58 Explanation: We can use 34 and 24 to sum 58 which is less than 60. Example 2:
Input: A = [10,20,30], K = 15 Output: -1 Explanation: In this case it’s not possible to get a pair sum less that 15.
Note:
1 <= A.length <= 100 1 <= A[i] <= 1000 1 <= K <= 2000
Solution
class Solution {
public int twoSumLessThanK(int[] A, int K) {
Arrays.sort(A);
int i = 0, j = A.length-1, max = -1;
while(i<j){
int sum = A[i] + A[j];
if(sum<K){
max = Math.max(sum, max);
i++;
}else{
j--;
}
}
return max;
}
}
146. LRU Cache
Description
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1. put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
The cache is initialized with a positive capacity.
Follow up: Could you do both operations in O(1) time complexity?
Example:
cache.put(1, 1); cache.put(2, 2); cache.get(1); // returns 1 cache.put(3, 3); // evicts key 2 cache.get(2); // returns -1 (not found) cache.put(4, 4); // evicts key 1 cache.get(1); // returns -1 (not found) cache.get(3); // returns 3 cache.get(4); // returns 4
Solution
class LRUCache {
class Node{
Node pre;
Node next;
int value;
int key;
}
Node head;
Node tail;
int capacity;
int count;
HashMap<Integer, Node> cache;
private void addNode(Node node){
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
private void removeNode(Node node){
Node preNode = node.pre;
Node nextNode = node.next;
preNode.next = nextNode;
nextNode.pre = preNode;
}
private void moveToHead(Node node){
this.removeNode(node);
this.addNode(node);
}
public LRUCache(int capacity) {
head = new Node();
tail = new Node();
head.next =tail;
head.pre = null;
tail.pre = head;
tail.next = null;
cache = new HashMap();
this.capacity = capacity;
this.count = 0;
}
public int get(int key) {
Node cur = cache.get(key);
if(cur == null){
return -1;
}
this.moveToHead(cur);
return cur.value;
}
public void put(int key, int value) {
if(cache.containsKey(key)){
Node cur = cache.get(key);
removeNode(cur);
cur.value = value;
addNode(cur);
cache.put(key,cur);
}else{
Node cur = new Node();
cur.key = key;
cur.value = value;
addNode(cur);
cache.put(key,cur);
count++;
}
while(count >capacity){
cache.remove(tail.pre.key);
removeNode(tail.pre);
count--;
}
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
56. Merge Intervals
Description
Given a collection of intervals, merge all overlapping intervals.
Example 1:
Input: [[1,3],[2,6],[8,10],[15,18]] Output: [[1,6],[8,10],[15,18]] Explanation: Since intervals [1,3] and [2,6] overlaps, merge them into [1,6]. Example 2:
Input: [[1,4],[4,5]] Output: [[1,5]] Explanation: Intervals [1,4] and [4,5] are considered overlapping.
Solution
import java.util.*;
class Solution {
public int[][] merge(int[][] intervals) {
if(intervals==null || intervals.length==0) return new int[0][0];
Arrays.sort(intervals,new Comparator<int[]>(){
public int compare(int[] o1, int[] o2) {
return o1[0]-o2[0];
}
});
int start = intervals[0][0],end = intervals[0][1];
List<int[]> res = new ArrayList<int[]>();
for(int i=1;i<intervals.length;i++){
int[] cur = intervals[i];
if(cur[0]<=end){
end = Math.max(cur[1], end);
}else{
res.add(new int[]{start,end});
start = cur[0];
end = cur[1];
}
}
res.add(new int[]{start,end});
int[][] resArray = new int[res.size()][2];
for(int i = 0;i<resArray.length;i++){
resArray[i] = res.get(i);
}
return resArray;
}
}
269. Alien Dictionary
Description
There is a new alien language which uses the latin alphabet. However, the order among letters are unknown to you. You receive a list of non-empty words from the dictionary, where words are sorted lexicographically by the rules of this new language. Derive the order of letters in this language.
Example 1:
Input: [ “wrt”, “wrf”, “er”, “ett”, “rftt” ]
Output: “wertf” Example 2:
Input: [ “z”, “x” ]
Output: “zx” Example 3:
Input: [ “z”, “x”, “z” ]
Output: “”
Explanation: The order is invalid, so return “”. Note:
You may assume all letters are in lowercase. You may assume that if a is a prefix of b, then a must appear before b in the given dictionary. If the order is invalid, return an empty string. There may be multiple valid order of letters, return any one of them is fine.
Solution
//main idea is to compare each word from the first letter that is different.
//use a set to store all letter that are behind this char.
//use topological sort to find the relative order.
class Solution {
public String alienOrder(String[] words) {
if (words == null || words.length == 0) return "";
HashMap<Character, Integer> degree = new HashMap();
HashMap<Character, Set<Character>> order = new HashMap<Character, Set<Character>>();
for (String word : words) {
for (char c : word.toCharArray()) {
degree.put(c, 0);
}
}
for (int idx = 0; idx < words.length - 1; idx++) {
String cur = words[idx];
String next = words[idx + 1];
int length = Math.min(cur.length(), next.length());
for(int i = 0;i<length;i++){
char c1 = cur.charAt(i);
char c2 = next.charAt(i);
if (c1 != c2) {
Set<Character> set = order.getOrDefault(c1, new HashSet<>());
//if (!set.contains(c2)) {
set.add(c2);
order.put(c1, set);
degree.put(c2, degree.get(c2) + 1);
//}
break;
}
}
}
StringBuilder sb = new StringBuilder();
Queue<Character> q = new LinkedList<>();
for(char c: degree.keySet()){
if(degree.get(c)==0){
q.add(c);
}
}
while(!q.isEmpty()){
char c = q.poll();
sb.append(c);
if(order.containsKey(c)){
for(char c2 :order.get(c)){
int d = degree.get(c2)-1;
degree.put(c2,d);
if(d==0) q.add(c2);
}
}
}
if(sb.length()!=degree.size()) return "";
return sb.toString();
}
public static void main(String[] args) {
Solution s = new Solution();
String[] in = new String[]{"wrt","wrf","er","ett","rftt"};
System.out.println(s.alienOrder(in));
}
}
2020-02-13
76. Minimum Window Substring
Description
Given a string S and a string T, find the minimum window in S which will contain all the characters in T in complexity O(n).
Example:
Input: S = “ADOBECODEBANC”, T = “ABC” Output: “BANC” Note:
If there is no such window in S that covers all characters in T, return the empty string “”. If there is such window, you are guaranteed that there will always be only one unique minimum window in S.
Solution
//main idea is to use count to see if the current range contains all chars in t.
//but need to be careful when duplicated char in s, so only update count when map.get(c) is larger than 0;
class Solution {
public String minWindow(String s, String t) {
if(s==null || t==null || s.length() == 0|| t.length()==0){
return "";
}
HashMap<Character, Integer> map = new HashMap();
int len = s.length();
int count = t.length(); // the number of characters that I need to match
for(char c : t.toCharArray()) map.put(c, map.getOrDefault(c, 0) + 1);
int minLeft = -1,minRight = -1;
int i = 0,j=0,minLen = s.length();
while(j<len){
char c = s.charAt(j);
if(map.containsKey(c)){
map.put(c,map.get(c)-1);
//if map.get(c) is already negative, means this one is duplicate, no need to decrement.
if(map.get(c)>=0) count--;
}
while(count == 0 && i<=j){
int curLen = j-i+1;
if(curLen<=minLen){
minLeft = i;
minRight = j;
minLen = curLen;
}
char leftC = s.charAt(i);
if(map.containsKey(leftC)){
map.put(leftC, map.get(leftC) + 1);
//if the previous map.get(c) is negative, means it's duplicated, there still will be another c in the range.
//so no need to increment.
if(map.get(leftC) >= 1) count++;
}
i++;
}
j++;
}
return minLeft==-1 && minRight==-1?"":s.substring(minLeft,minRight+1);
}
}
560. Subarray Sum Equals K
Description
Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
Example 1: Input:nums = [1,1,1], k = 2 Output: 2 Note: The length of the array is in range [1, 20,000]. The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
Solution
//main idea is to solve this problem is SUM[i, j]. So if we know SUM[0, i - 1] and SUM[0, j], then we can easily get SUM[i, j]. To achieve this, we just need to go through the array, calculate the current sum and save number of all seen PreSum to a HashMap. Time complexity O(n), Space complexity O(n).
class Solution {
public int subarraySum(int[] nums, int k) {
if(nums == null || nums.length == 0){
return 0;
}
HashMap<Integer,Integer> preSum = new HashMap();
preSum.put(0,1);
int res = 0, sum =0;
for(int i = 0;i<nums.length;i++){
int cur = nums[i];
sum+=cur;
if(preSum.containsKey(sum-k)){
res += preSum.get(sum-k);
}
preSum.put(sum,preSum.getOrDefault(sum,0)+1);
}
return res;
}
}
139. Word Break
Description
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, determine if s can be segmented into a space-separated sequence of one or more dictionary words.
Note:
The same word in the dictionary may be reused multiple times in the segmentation. You may assume the dictionary does not contain duplicate words. Example 1:
Input: s = “leetcode”, wordDict = [“leet”, “code”] Output: true Explanation: Return true because “leetcode” can be segmented as “leet code”. Example 2:
Input: s = “applepenapple”, wordDict = [“apple”, “pen”] Output: true Explanation: Return true because “applepenapple” can be segmented as “apple pen apple”. Note that you are allowed to reuse a dictionary word. Example 3:
Input: s = “catsandog”, wordDict = [“cats”, “dog”, “sand”, “and”, “cat”] Output: false
Solution
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
HashSet<String> dict = new HashSet<>(wordDict);
int len = s.length();
boolean[] dp = new boolean[len+1];
dp[0] = true;
//note: j is always 1 less than i, so in the range 0->i-1, dp[] are all valid.
//so just need to check if dp[j] and substring(j,i) are both valid then dp[i] is valid.
for(int i = 1;i<=len;i++){
for(int j = 0;j<i;j++){
if(dp[j] && dict.contains(s.substring(j,i))){
dp[i] = true;
break;
}
}
}
return dp[len];
}
}
2020-02-16
986. Interval List Intersections
Description
Given two lists of closed intervals, each list of intervals is pairwise disjoint and in sorted order.
Return the intersection of these two interval lists.
(Formally, a closed interval {a, b} (with a <= b) denotes the set of real numbers x with a <= x <= b. The intersection of two closed intervals is a set of real numbers that is either empty, or can be represented as a closed interval. For example, the intersection of [1, 3] and [2, 4] is [2, 3].)
Example 1:
Input: A = [[0,2],[5,10],[13,23],[24,25]], B = [[1,5],[8,12],[15,24],[25,26]] Output: [[1,2],[5,5],[8,10],[15,23],[24,24],[25,25]] Reminder: The inputs and the desired output are lists of Interval objects, and not arrays or lists.
Note:
0 <= A.length < 1000 0 <= B.length < 1000 0 <= A[i].start, A[i].end, B[i].start, B[i].end < 10^9
Main Idea
main idea is to use two pointer and iterate through. start is the max among two starts, end is the min among two ends. everytime end >= start, means there’s a intefval. which end is reached, should increment.
Solution
class Solution {
public int[][] intervalIntersection(int[][] A, int[][] B) {
if (A == null || A.length == 0 || B == null || B.length == 0) {
return new int[0][0];
}
int alen = A.length, blen = B.length;
int i = 0, j = 0;
List<int[]> res = new ArrayList();
while( i<alen && j<blen){
int[] a = A[i];
int[] b = B[j];
int start = Math.max(a[0],b[0]);
int end = Math.min(a[1],b[1]);
if(end >= start){
res.add(new int[]{start, end});
}
if(end == a[1]) i++;
if(end == b[1]) j++;
}
int[][] resArray = new int[res.size()][2];
for(int idx = 0;idx<res.size();idx++){
resArray[idx] = res.get(idx);
}
return resArray;
}
}
140. Word Break II
Description
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, add spaces in s to construct a sentence where each word is a valid dictionary word. Return all such possible sentences.
Note:
The same word in the dictionary may be reused multiple times in the segmentation. You may assume the dictionary does not contain duplicate words. Example 1:
Input: s = “catsanddog” wordDict = [“cat”, “cats”, “and”, “sand”, “dog”] Output: [ “cats and dog”, “cat sand dog” ] Example 2:
Input: s = “pineapplepenapple” wordDict = [“apple”, “pen”, “applepen”, “pine”, “pineapple”] Output: [ “pine apple pen apple”, “pineapple pen apple”, “pine applepen apple” ] Explanation: Note that you are allowed to reuse a dictionary word. Example 3:
Input: s = “catsandog” wordDict = [“cats”, “dog”, “sand”, “and”, “cat”] Output: []
Main Idea
maintain a map to avoid duplicate search.
break the string into two part, if the first part is in the dict, then search into the remaining part and return the all possible break for the remaining part.
glue all the result together and return.
before return add to map.
Solution
class Solution {
HashMap<String, List<String>> map;
HashSet<String> wordSet;
public List<String> wordBreak(String s, List<String> wordDict) {
map = new HashMap();
wordSet = new HashSet(wordDict);
return helper(s);
}
public List<String> helper(String s){
List<String> res = new ArrayList();
if(s == null || s.isEmpty()) return res;
if(map.containsKey(s)) return map.get(s);
if(wordSet.contains(s)) {
res.add(s);
}
for(int i = 1;i<s.length();i++){
String t = s.substring(0, i);
if(wordSet.contains(t)){
List<String> temp = helper(s.substring(i));
if(temp!=null && temp.size()!=0){
for(int j = 0;j<temp.size();j++){
res.add(t+" "+temp.get(j));
}
}
}
}
map.put(s,res);
return res;
}
}
1249. Minimum Remove to Make Valid Parentheses
Description
Given a string s of ‘(‘ , ‘)’ and lowercase English characters.
Your task is to remove the minimum number of parentheses ( ‘(‘ or ‘)’, in any positions ) so that the resulting parentheses string is valid and return any valid string.
Formally, a parentheses string is valid if and only if:
It is the empty string, contains only lowercase characters, or It can be written as AB (A concatenated with B), where A and B are valid strings, or It can be written as (A), where A is a valid string.
Example 1:
Input: s = “lee(t(c)o)de)” Output: “lee(t(c)o)de” Explanation: “lee(t(co)de)” , “lee(t(c)ode)” would also be accepted. Example 2:
Input: s = “a)b(c)d” Output: “ab(c)d” Example 3:
Input: s = “))((“ Output: “” Explanation: An empty string is also valid. Example 4:
Input: s = “(a(b(c)d)” Output: “a(b(c)d)”
Constraints:
1 <= s.length <= 10^5 s[i] is one of ‘(‘ , ‘)’ and lowercase English letters.
Main Idea
Use stack to record the index of left par, everytime meet a right, pop, make a pair.
- if the right one, and st is empty, means it’s not valid, marked it.
- if after the iteration, st is still not empty, means left par in the stack is not valid, mark all.
- remove all char marked invalid.
Solution
class Solution {
public String minRemoveToMakeValid(String s) {
if(s == null || s.length() == 0){
return s;
}
Stack<Integer> st = new Stack();
StringBuilder sb = new StringBuilder(s);
for(int i = 0;i<s.length();i++){
char c = s.charAt(i);
if(c == '('){
st.push(i);
}else if(c == ')'){
if(st.isEmpty()){
sb.setCharAt(i,'*');
}else{
st.pop();
}
}
}
while(!st.isEmpty()){
sb.setCharAt(st.pop(),'*');
}
return sb.toString().replaceAll("\\*","");
}
}
34. Find First and Last Position of Element in Sorted Array
Description
Given an array of integers nums sorted in ascending order, find the starting and ending position of a given target value.
Your algorithm’s runtime complexity must be in the order of O(log n).
If the target is not found in the array, return [-1, -1].
Example 1:
Input: nums = [5,7,7,8,8,10], target = 8 Output: [3,4] Example 2:
Input: nums = [5,7,7,8,8,10], target = 6 Output: [-1,-1]
Main Idea
The last step before end, there will be only two elements, which is [i,j].
There will only be six scenarios which are:
- [t,t+1]
- [t,t]
- [t-1,t]
- [t-2,t-1]
- [t-1,t+1]
- [t+1,t-2]
4-6 are all invalid, so the return value will always not equals target, we don’t need to take care of.
For 1-3, if we are lokking for left bound:
i=mid, j = mid+1
- [t,t+1]
- [t,t]
- [t-1,t]
1,2: a[mid] >= target, return i=mid, j =mid;
3: a[mid] < target, return i = mid+1, j = mid+1;
so the returned i will be the answer.
Looking for right boundary:
We need to bias the mid to avoid the i stuck in the loop.
So mid = (i+j)/2 + 1;
i=mid-1, j = mid
- [t,t+1]
- [t,t]
- [t-1,t]
for 1: a[mid] > t: return i = mid-1, j = mid-1;
for 2,3 : a[mid] <= t: return i = mid, j = mid;
now returned j is the answer.
So In order to find a solution for binary search, think about the last step.
The problem can be simply broken down as two binary searches for the begining and end of the range, respectively:
First let’s find the left boundary of the range. We initialize the range to [i=0, j=n-1]. In each step, calculate the middle element [mid = (i+j)/2]. Now according to the relative value of A[mid] to target, there are three possibilities:
If A[mid] < target, then the range must begins on the right of mid (hence i = mid+1 for the next iteration) If A[mid] > target, it means the range must begins on the left of mid (j = mid-1) If A[mid] = target, then the range must begins on the left of or at mid (j= mid) Since we would move the search range to the same side for case 2 and 3, we might as well merge them as one single case so that less code is needed:
2*. If A[mid] >= target, j = mid;
Surprisingly, 1 and 2* are the only logic you need to put in loop while (i < j). When the while loop terminates, the value of i/j is where the start of the range is. Why?
No matter what the sequence originally is, as we narrow down the search range, eventually we will be at a situation where there are only two elements in the search range. Suppose our target is 5, then we have only 7 possible cases:
case 1: [5 7] (A[i] = target < A[j]) case 2: [5 3] (A[i] = target > A[j]) case 3: [5 5] (A[i] = target = A[j]) case 4: [3 5] (A[j] = target > A[i]) case 5: [3 7] (A[i] < target < A[j]) case 6: [3 4] (A[i] < A[j] < target) case 7: [6 7] (target < A[i] < A[j]) For case 1, 2 and 3, if we follow the above rule, since mid = i => A[mid] = target in these cases, then we would set j = mid. Now the loop terminates and i and j both point to the first 5.
For case 4, since A[mid] < target, then set i = mid+1. The loop terminates and both i and j point to 5.
For all other cases, by the time the loop terminates, A[i] is not equal to 5. So we can easily know 5 is not in the sequence if the comparison fails.
In conclusion, when the loop terminates, if A[i]==target, then i is the left boundary of the range; otherwise, just return -1;
For the right of the range, we can use a similar idea. Again we can come up with several rules:
If A[mid] > target, then the range must begins on the left of mid (j = mid-1) If A[mid] < target, then the range must begins on the right of mid (hence i = mid+1 for the next iteration) If A[mid] = target, then the range must begins on the right of or at mid (i= mid) Again, we can merge condition 2 and 3 into:
2* If A[mid] <= target, then i = mid; However, the terminate condition on longer works this time. Consider the following case:
[5 7], target = 5 Now A[mid] = 5, then according to rule 2, we set i = mid. This practically does nothing because i is already equal to mid. As a result, the search range is not moved at all!
The solution is by using a small trick: instead of calculating mid as mid = (i+j)/2, we now do:
mid = (i+j)/2+1 Why does this trick work? When we use mid = (i+j)/2, the mid is rounded to the lowest integer. In other words, mid is always biased towards the left. This means we could have i == mid when j - i == mid, but we NEVER have j == mid. So in order to keep the search range moving, you must make sure the new i is set to something different than mid, otherwise we are at the risk that i gets stuck. But for the new j, it is okay if we set it to mid, since it was not equal to mid anyways. Our two rules in search of the left boundary happen to satisfy these requirements, so it works perfectly in that situation. Similarly, when we search for the right boundary, we must make sure i won’t get stuck when we set the new i to i = mid. The easiest way to achieve this is by making mid biased to the right, i.e. mid = (i+j)/2+1.
Solution
class Solution {
public int[] searchRange(int[] nums, int target) {
int[] res = new int[]{-1,-1};
if(nums == null || nums.length == 0) return res;
int i = 0, j = nums.length - 1;
while(i<j){
int mid = i + (j-i)/2;
if(nums[mid]<target) i = mid+1;
else j = mid;
}
if(nums[i]!= target) return res;
res[0] = i;
j = nums.length-1;
while(i<j){
int mid = i + (j-i)/2 + 1;
if(nums[mid] > target) j = mid - 1;
else i = mid;
}
res[1] = j;
return res;
}
}
158. Read N Characters Given Read4 II - Call multiple times
Description
Given a file and assume that you can only read the file using a given method read4, implement a method read to read n characters. Your method read may be called multiple times.
Method read4:
The API read4 reads 4 consecutive characters from the file, then writes those characters into the buffer array buf.
The return value is the number of actual characters read.
Note that read4() has its own file pointer, much like FILE *fp in C.
Definition of read4:
Parameter: char[] buf
Returns: int
Note: buf[] is destination not source, the results from read4 will be copied to buf[] Below is a high level example of how read4 works:
File file(“abcdefghijk”); // File is “abcdefghijk”, initially file pointer (fp) points to ‘a’ char[] buf = new char[4]; // Create buffer with enough space to store characters read4(buf); // read4 returns 4. Now buf = “abcd”, fp points to ‘e’ read4(buf); // read4 returns 4. Now buf = “efgh”, fp points to ‘i’ read4(buf); // read4 returns 3. Now buf = “ijk”, fp points to end of file
Method read:
By using the read4 method, implement the method read that reads n characters from the file and store it in the buffer array buf. Consider that you cannot manipulate the file directly.
The return value is the number of actual characters read.
Definition of read:
Parameters: char[] buf, int n
Returns: int
Note: buf[] is destination not source, you will need to write the results to buf[]
Example 1:
File file(“abc”); Solution sol; // Assume buf is allocated and guaranteed to have enough space for storing all characters from the file. sol.read(buf, 1); // After calling your read method, buf should contain “a”. We read a total of 1 character from the file, so return 1. sol.read(buf, 2); // Now buf should contain “bc”. We read a total of 2 characters from the file, so return 2. sol.read(buf, 1); // We have reached the end of file, no more characters can be read. So return 0. Example 2:
File file(“abc”); Solution sol; sol.read(buf, 4); // After calling your read method, buf should contain “abc”. We read a total of 3 characters from the file, so return 3. sol.read(buf, 1); // We have reached the end of file, no more characters can be read. So return 0.
Note:
Consider that you cannot manipulate the file directly, the file is only accesible for read4 but not for read. The read function may be called multiple times. Please remember to RESET your class variables declared in Solution, as static/class variables are persisted across multiple test cases. Please see here for more details. You may assume the destination buffer array, buf, is guaranteed to have enough space for storing n characters. It is guaranteed that in a given test case the same buffer buf is called by read.
Solution
/**
* The read4 API is defined in the parent class Reader4.
* int read4(char[] buf);
*/
public class Solution extends Reader4 {
/**
* @param buf Destination buffer
* @param n Number of characters to read
* @return The number of actual characters read
*/
Queue<Character> q = new LinkedList();
public int read(char[] buf, int n) {
int remain = n;
int i = 0;
while(remain > 0){
if(q.size()<4){
char[] b = new char[4];
int c = read4(b);
for(int k = 0;k<c;k++){
q.add(b[k]);
}
}
for(int k = 0; k<4 && remain > 0;k++,remain--){
if(q.isEmpty()){
return n-remain;
}
buf[i++] = q.poll();
}
}
return n-remain;
}
}
438. Find All Anagrams in a String
Destination
Given a string s and a non-empty string p, find all the start indices of p’s anagrams in s.
Strings consists of lowercase English letters only and the length of both strings s and p will not be larger than 20,100.
The order of output does not matter.
Example 1:
Input: s: “cbaebabacd” p: “abc”
Output: [0, 6]
Explanation: The substring with start index = 0 is “cba”, which is an anagram of “abc”. The substring with start index = 6 is “bac”, which is an anagram of “abc”. Example 2:
Input: s: “abab” p: “ab”
Output: [0, 1, 2]
Explanation: The substring with start index = 0 is “ab”, which is an anagram of “ab”. The substring with start index = 1 is “ba”, which is an anagram of “ab”. The substring with start index = 2 is “ab”, which is an anagram of “ab”.
Main Idea
use a int[26] and a count to record the status. if int[c-‘a’] is larger than 0, means it’s not in the cur range. if is less than 0, means there’s duplicate. iterate through the array, each step, pop out the previous one and take a new one.
maintain the dict and count.
If the count is 0, means the current range include all char in p, so record it in the res.
Solution
class Solution {
public List<Integer> findAnagrams(String s, String p) {
int[] dict = new int[26];
int count = 0;
HashSet<Character> set = new HashSet();
for (char c : p.toCharArray()) {
dict[c - 'a']++;
count++;
set.add(c);
}
List<Integer> res = new ArrayList();
int len = p.length();
for (int i = 0; i < s.length(); i++) {
if (i < len) {
char c = s.charAt(i);
if (set.contains(c)) {
dict[c - 'a']--;
if (dict[c - 'a'] >= 0) {
count--;
}
}
} else {
char cur = s.charAt(i);
char pre = s.charAt(i-len);
if (set.contains(pre)) {
dict[pre - 'a']++;
if (dict[pre - 'a'] > 0) {
count++;
}
}
if (set.contains(cur)) {
dict[cur - 'a']--;
if (dict[cur - 'a'] >= 0) {
count--;
}
}
}
if (count == 0) {
res.add(i - len + 1);
}
}
return res;
}
}
2020-02-17
426. Convert Binary Search Tree to Sorted Doubly Linked List
Description
Convert a Binary Search Tree to a sorted Circular Doubly-Linked List in place.
You can think of the left and right pointers as synonymous to the predecessor and successor pointers in a doubly-linked list. For a circular doubly linked list, the predecessor of the first element is the last element, and the successor of the last element is the first element.
We want to do the transformation in place. After the transformation, the left pointer of the tree node should point to its predecessor, and the right pointer should point to its successor. You should return the pointer to the smallest element of the linked list.
Example 1:
Input: root = [4,2,5,1,3]
Output: [1,2,3,4,5]
Explanation: The figure below shows the transformed BST. The solid line indicates the successor relationship, while the dashed line means the predecessor relationship.
Example 2:
Input: root = [2,1,3] Output: [1,2,3] Example 3:
Input: root = [] Output: [] Explanation: Input is an empty tree. Output is also an empty Linked List. Example 4:
Input: root = [1] Output: [1]
Constraints:
-1000 <= Node.val <= 1000 Node.left.val < Node.val < Node.right.val All values of Node.val are unique. 0 <= Number of Nodes <= 2000
Main Idea
the mian idea is to do a inorder traversal. At each step, will connnect pre and cur, then pre= cur.
Solution
class Solution {
Node pre = null;
public Node treeToDoublyList(Node root) {
if(root == null){
return null;
}
Node dummy = new Node(0,null,null);
pre = dummy;
helper(root);
pre.right = dummy.right;
dummy.right.left = pre;
return dummy.right;
}
//basiclly a inorder traversal.
private void helper(Node root){
if(root == null){
return;
}
helper(root.left);
pre.right = root;
root.left = pre;
pre = root;
helper(root.right);
}
}
133. Clone Graph
Description
Given a reference of a node in a connected undirected graph.
Return a deep copy (clone) of the graph.
Each node in the graph contains a val (int) and a list (List[Node]) of its neighbors.
class Node {
public int val;
public List
Solution
//recurrsion is more clear than queue;
class Solution {
Map<Node,Node> map = new HashMap();
public Node cloneGraph(Node node) {
if(node ==null){
return null;
}
if(map.containsKey(node)) return map.get(node);
Node res = new Node(node.val);
map.put(node, res);
for(Node n: node.neighbors){
res.neighbors.add(cloneGraph(n));
}
return res;
}
}
340. Longest Substring with At Most K Distinct Characters
Description
Given a string, find the length of the longest substring T that contains at most k distinct characters.
Example 1:
Input: s = “eceba”, k = 2 Output: 3 Explanation: T is “ece” which its length is 3. Example 2:
Input: s = “aa”, k = 1 Output: 2 Explanation: T is “aa” which its length is 2.
Main Solution
still a sliding window problem, use two pointer, right pointer will increment by 1 each time, and at each step, will check if count is larger than k.
if count is larger than k, means more than k unique char is in the current range, so we need to increment left i to get rid of until count less/equal k.
use a while loop to check dict[i], if –dict[i]==0, means that after get rid of the current char at i, it’s become 0 and no such char exist in the range.
So the count is now equals to k. (Since we check every step, we can make sure count is either k or k+1)
Solution
class Solution {
public int lengthOfLongestSubstringKDistinct(String s, int k) {
int[] dict = new int[256];
int count = 0;
int i=0,len = s.length();
int res = 0;
for(int j = 0;j<len;j++){
if(dict[s.charAt(j)]==0){
count++;
}
dict[s.charAt(j)]++;
if(count>k){
while(--dict[s.charAt(i++)]>0);
count--;
}
res = Math.max(res, j-i+1);
}
return res;
}
}
2020-02-18
1060. Missing Element in Sorted Array
Description
Given a sorted array A of unique numbers, find the K-th missing number starting from the leftmost number of the array.
Example 1:
Input: A = [4,7,9,10], K = 1 Output: 5 Explanation: The first missing number is 5. Example 2:
Input: A = [4,7,9,10], K = 3 Output: 8 Explanation: The missing numbers are [5,6,8,…], hence the third missing number is 8. Example 3:
Input: A = [1,2,4], K = 3 Output: 6 Explanation: The missing numbers are [3,5,6,7,…], hence the third missing number is 6.
Note:
1 <= A.length <= 50000 1 <= A[i] <= 1e7 1 <= K <= 1e8
Main Idea
use binary search to find the right place to start, for i, i+1, missingleft for i is smaller than k while misingleft for i+1 is larger than k.
Solution
class Solution {
public int missingElement(int[] nums, int k) {
int n = nums.length;
int l = 0;
int h = n - 1;
int missingNum = nums[n - 1] - nums[0] + 1 - n;
if (missingNum < k) {
return nums[n - 1] + k - missingNum;
}
while (l < h - 1) {
int m = l + (h - l) / 2;
int missing = nums[m] - nums[l] - (m - l);
if (missing >= k) {
// when the number is larger than k, then the index won't be located in (m, h]
h = m;
} else {
// when the number is smaller than k, then the index won't be located in [l, m), update k -= missing
k -= missing;
l = m;
}
}
return nums[l] + k;
}
}
282. Expression Add Operators
Description
Given a string that contains only digits 0-9 and a target value, return all possibilities to add binary operators (not unary) +, -, or * between the digits so they evaluate to the target value.
Example 1:
Input: num = “123”, target = 6 Output: [“1+2+3”, “1*2*3”] Example 2:
Input: num = “232”, target = 8 Output: [“2*3+2”, “2+3*2”] Example 3:
Input: num = “105”, target = 5 Output: [“1*0+5”,”10-5”] Example 4:
Input: num = “00”, target = 0 Output: [“0+0”, “0-0”, “0*0”] Example 5:
Input: num = “3456237490”, target = 9191 Output: []
Main Idea
use iteration to find all possible solution.
Solution
class Solution {
public List<String> addOperators(String num, int target) {
List<String> res = new ArrayList();
helper(num, 0,target,0,0,"",res);
return res;
}
private void helper(String num, int idx, int target, int sum,int prev, String temp, List<String> res){
//end case.
if(idx == num.length()){
if(target == sum){
res.add(temp);
}
return;
}
//use for loop to find number larger than 10.
for(int i = idx; i < num.length(); i++){
String num_t = num.substring(idx, i+1);
//invalid number start with 0.
if(num_t.length()>1 && num_t.charAt(0)=='0') break;
//NOTE: num-t maybe too large, need to use long or even BigInteger.
long a =Long.parseLong(num_t);
//the very first step should be taken care of.
if(temp.length()==0){
helper(num,i+1,target,a, a,""+a,res);
}else{
helper(num,i+1,target,sum+a, a, temp + "+"+a,res);
helper(num,i+1,target,sum-a, -a, temp + "-"+a,res);
//prev is important to revert, so the next step sum is (sum-prev)+prev*a, and next pre is prev*a.
helper(num,i+1,target,(sum-prev) + prev * a, prev*a, temp + "*"+a,res);
}
}
}
}
2020-02-19
785. Is Graph Bipartite?
Description
Given an undirected graph, return true if and only if it is bipartite.
Recall that a graph is bipartite if we can split it’s set of nodes into two independent subsets A and B such that every edge in the graph has one node in A and another node in B.
The graph is given in the following form: graph[i] is a list of indexes j for which the edge between nodes i and j exists. Each node is an integer between 0 and graph.length - 1. There are no self edges or parallel edges: graph[i] does not contain i, and it doesn’t contain any element twice.
Example 1: Input: [[1,3], [0,2], [1,3], [0,2]] Output: true Explanation: The graph looks like this: 0—-1 | | | | 3—-2 We can divide the vertices into two groups: {0, 2} and {1, 3}. Example 2: Input: [[1,2,3], [0,2], [0,1,3], [0,2]] Output: false Explanation: The graph looks like this: 0—-1 | \ | | \ | 3—-2 We cannot find a way to divide the set of nodes into two independent subsets.
Note:
graph will have length in range [1, 100]. graph[i] will contain integers in range [0, graph.length - 1]. graph[i] will not contain i or duplicate values. The graph is undirected: if any element j is in graph[i], then i will be in graph[j].
Main Idea
To use BFS to search, the next level point should not have the same color as the current one.
NOTE: need to iterate through all points as there might be more than one graph.
Solution
class Solution {
public boolean isBipartite(int[][] graph) {
int len = graph.length;
int[] color = new int[len];
//need to iterate through all points as there might be more than one graph.
for(int i = 0;i<len;i++){
//already visited, skip.
if(color[i]!=0){
continue;
}
Queue<Integer> q = new LinkedList();
q.offer(i);
color[i] = 1;
while(!q.isEmpty()){
int cur = q.poll();
for(int next : graph[cur]){
//unvisited, color it and push to queue.
if(color[next]==0){
q.offer(next);
color[next] = -color[cur];
//already visited, check validation.
}else if(color[next]==color[cur]){
return false;
}
}
}
}
return true;
}
}
278. First Bad Version
Description
You are a product manager and currently leading a team to develop a new product. Unfortunately, the latest version of your product fails the quality check. Since each version is developed based on the previous version, all the versions after a bad version are also bad.
Suppose you have n versions [1, 2, …, n] and you want to find out the first bad one, which causes all the following ones to be bad.
You are given an API bool isBadVersion(version) which will return whether version is bad. Implement a function to find the first bad version. You should minimize the number of calls to the API.
Example:
Given n = 5, and version = 4 is the first bad version.
call isBadVersion(3) -> false call isBadVersion(5) -> true call isBadVersion(4) -> true
Then 4 is the first bad version.
Main Idea
Binary Search, similar to find the first position of a target.
Solution
/* The isBadVersion API is defined in the parent class VersionControl.
boolean isBadVersion(int version); */
public class Solution extends VersionControl {
public int firstBadVersion(int n) {
int i=1, j = n;
while(i<j){
//take care of the overflow problem.
int mid = i + (j-i)/2;
if(!isBadVersion(mid)){
i = mid + 1;
}else{
j = mid;
}
}
return i;
}
}
398. Random Pick Index
Description
Given an array of integers with possible duplicates, randomly output the index of a given target number. You can assume that the given target number must exist in the array.
Note: The array size can be very large. Solution that uses too much extra space will not pass the judge.
Example:
int[] nums = new int[] {1,2,3,3,3}; Solution solution = new Solution(nums);
// pick(3) should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning. solution.pick(3);
// pick(1) should return 0. Since in the array only nums[0] is equal to 1. solution.pick(1);
Main Idea
{1,2,3,3,3} with target 3, you want to select 2,3,4 with a probability of 1/3 each.
2 : It’s probability of selection is 1 * (1/2) * (2/3) = 1/3
3 : It’s probability of selection is (1/2) * (2/3) = 1/3
4 : It’s probability of selection is just 1/3
So they are each randomly selected.
Solution
class Solution {
int[] nums;
Random rnd;
public Solution(int[] nums) {
this.nums = nums;
rnd = new Random();
}
public int pick(int target) {
int count = 0;
int res = -1;
for(int i = 0;i<nums.length;i++){
if(nums[i]!=target){
continue;
}
if(rnd.nextInt(++count)==0){
res = i;
}
}
return res;
}
}
1007. Minimum Domino Rotations For Equal Row
Description
In a row of dominoes, A[i] and B[i] represent the top and bottom halves of the i-th domino. (A domino is a tile with two numbers from 1 to 6 - one on each half of the tile.)
We may rotate the i-th domino, so that A[i] and B[i] swap values.
Return the minimum number of rotations so that all the values in A are the same, or all the values in B are the same.
If it cannot be done, return -1.
Example 1:
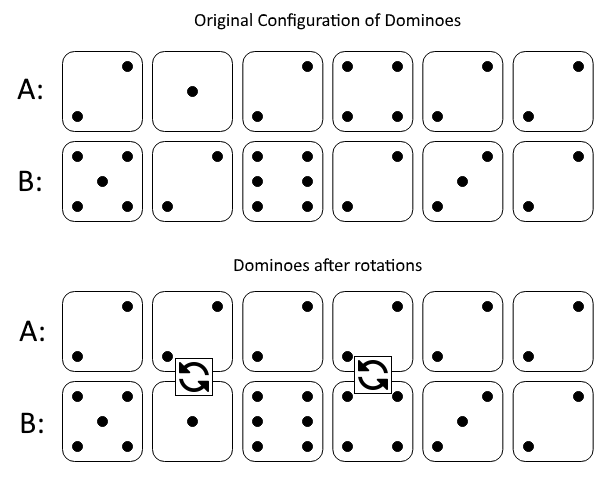
Input: A = [2,1,2,4,2,2], B = [5,2,6,2,3,2] Output: 2 Explanation: The first figure represents the dominoes as given by A and B: before we do any rotations. If we rotate the second and fourth dominoes, we can make every value in the top row equal to 2, as indicated by the second figure. Example 2:
Input: A = [3,5,1,2,3], B = [3,6,3,3,4] Output: -1 Explanation: In this case, it is not possible to rotate the dominoes to make one row of values equal.
Note:
1 <= A[i], B[i] <= 6 2 <= A.length == B.length <= 20000
Solution
class Solution {
public int minDominoRotations(int[] A, int[] B) {
int[] countA = new int[7];
int[] countB = new int[7];
int[] same = new int[7];
int len = A.length;
int res = Integer.MAX_VALUE;
for(int i = 0;i<len;i++){
countA[A[i]]++;
countB[B[i]]++;
if(A[i]==B[i]){
same[A[i]]++;
}
}
for(int i = 1;i<7;i++){
if(countA[i] + countB[i] - same[i] == len){
res = Math.min(res, len - Math.max(countA[i],countB[i]));
}
}
return res==Integer.MAX_VALUE? -1: res;
}
}
1048. Longest String Chain
Description
Given a list of words, each word consists of English lowercase letters.
Let’s say word1 is a predecessor of word2 if and only if we can add exactly one letter anywhere in word1 to make it equal to word2. For example, “abc” is a predecessor of “abac”.
A word chain is a sequence of words [word_1, word_2, …, word_k] with k >= 1, where word_1 is a predecessor of word_2, word_2 is a predecessor of word_3, and so on.
Return the longest possible length of a word chain with words chosen from the given list of words.
Example 1:
Input: [“a”,”b”,”ba”,”bca”,”bda”,”bdca”] Output: 4 Explanation: one of the longest word chain is “a”,”ba”,”bda”,”bdca”.
Note:
1 <= words.length <= 1000 1 <= words[i].length <= 16 words[i] only consists of English lowercase letters.
Main Idea
for each word, iterate through all the possible prev word, using a map to see the possible best length.
Solution
class Solution {
public int longestStrChain(String[] words) {
HashMap<String,Integer> map = new HashMap();
int res = 1;
Arrays.sort(words,(a,b)->(a.length()-b.length()));
for(String word : words){
int len = word.length();
int localBest = -1;
for(int i = 0;i<len;i++){
//remove char at i.
String prev = word.substring(0,i)+word.substring(i+1);
//find the longest length of this prev, if prev exist, will increment by q and record as localbest.
localBest = Math.max(localBest, map.getOrDefault(prev,0)+1);
}
map.put(word, localBest);
res = Math.max(res, localBest);
}
return res;
}
}
221. Maximal Square
Description
Given a 2D binary matrix filled with 0’s and 1’s, find the largest square containing only 1’s and return its area.
Example:
Input:
1 0 1 0 0
1 0 1 1 1
1 1 1 1 1
1 0 0 1 0
Output: 4
Main idea
1 0 1 0 0
1 0 1 1 1
1 1 1 1 1
1 0 1 1 1
1 0 1 0 0
1 0 1 1 1
1 1 1 2 2
1 0 1 2 3
Solution
class Solution {
public int maximalSquare(char[][] matrix) {
int yLen = matrix.length;
if(yLen==0) return 0;
int xLen = matrix[0].length;
int[][] dp = new int[yLen][xLen];
int res = 0;
for(int x = 0; x<xLen;x++){
for(int y = 0; y<yLen;y++){
//need to take care of the edge, also if there's a single 1, res will be minimum 1.
if(y==0 || x==0 || matrix[y][x] == '0'){
dp[y][x] = matrix[y][x]-'0';
}else{
//only if the three corners of the cur point is the same/non-zero, the current point will record a square.
dp[y][x] = Math.min(dp[y-1][x-1], Math.min(dp[y-1][x],dp[y][x-1])) + 1;
}
res = Math.max(res,dp[y][x]);
}
}
return res*res;
}
}
68. Text Justification
Description
Given an array of words and a width maxWidth, format the text such that each line has exactly maxWidth characters and is fully (left and right) justified.
You should pack your words in a greedy approach; that is, pack as many words as you can in each line. Pad extra spaces ‘ ‘ when necessary so that each line has exactly maxWidth characters.
Extra spaces between words should be distributed as evenly as possible. If the number of spaces on a line do not divide evenly between words, the empty slots on the left will be assigned more spaces than the slots on the right.
For the last line of text, it should be left justified and no extra space is inserted between words.
Note:
A word is defined as a character sequence consisting of non-space characters only. Each word’s length is guaranteed to be greater than 0 and not exceed maxWidth. The input array words contains at least one word. Example 1:
Input:
words = ["This", "is", "an", "example", "of", "text", "justification."]
maxWidth = 16
Output:
[
"This is an",
"example of text",
"justification. "
]
Example 2:
Input:
words = ["What","must","be","acknowledgment","shall","be"]
maxWidth = 16
Output:
[
"What must be",
"acknowledgment ",
"shall be "
]
Explanation: Note that the last line is "shall be " instead of "shall be",
because the last line must be left-justified instead of fully-justified.
Note that the second line is also left-justified becase it contains only one word.
Example 3:
Input:
words = ["Science","is","what","we","understand","well","enough","to","explain",
"to","a","computer.","Art","is","everything","else","we","do"]
maxWidth = 20
Output:
[
"Science is what we",
"understand well",
"enough to explain to",
"a computer. Art is",
"everything else we",
"do "
]
Main Idea
main idea is to:
- split each word into a subset so we can justify.
- when justify, first calcualte how many space between two word, also use remainder to add extra space in the first {remainder} space.
- if it’s the last line, than only one space should be suffice, and pad the rest.
- if left==right, just one word, pad it.
- after insert spaces, pad the string.
Solution
class Solution {
public List<String> fullJustify(String[] words, int maxWidth) {
int left = 0;
List<String> res = new ArrayList();
while(left < words.length){
//find the index of the last word in this subset.
int right = findRight(left, words, maxWidth);
//generate the justified string.
res.add(justify(left, right, words,maxWidth));
//go to next available word.
left = right + 1;
}
return res;
}
private int findRight(int left, String[] words, int maxWidth){
int right = left;
//insert first word as it does not have a extra space before it.
int sum = words[right++].length();
//sum will sum up until meet maxWidth.
while(right < words.length && (sum + 1 + words[right].length())<= maxWidth){
sum += (1 + words[right++].length());
}
//cur right is the first one that's invalid.
return right - 1;
}
private String justify(int left, int right, String[] words, int maxWidth){
//only one word, just pad it.
if (right - left == 0) return padString(words[left], maxWidth);
//if it's last line no need to take care of the number of space.
boolean isLastLine = right == words.length-1;
int countWord = 0;
for(int i = left;i<=right;i++){
countWord += words[i].length();
}
//number of gaps.
int space = maxWidth - countWord;
//how many space for a gap.
int spaceEachWord = isLastLine? 1 : space / (right-left);
//first {remain} gaps should have an extra space to even it out.
int remain = isLastLine? 0: space % (right-left);
StringBuilder sb = new StringBuilder();
for(int i = left;i<=right;i++){
sb.append(words[i]).append(generateSpace(spaceEachWord + (remain-- > 0?1:0)));
}
return padString(sb.toString().trim(),maxWidth);
}
private String generateSpace(int count){
StringBuilder sb = new StringBuilder();
for(int i = 0;i<count;i++){
sb.append(" ");
}
return sb.toString();
}
private String padString(String str, int maxWidth){
return str + generateSpace(maxWidth - str.length());
}
}
642. Design Search Autocomplete System
Description
Design a search autocomplete system for a search engine. Users may input a sentence (at least one word and end with a special character ‘#’). For each character they type except ‘#’, you need to return the top 3 historical hot sentences that have prefix the same as the part of sentence already typed. Here are the specific rules:
The hot degree for a sentence is defined as the number of times a user typed the exactly same sentence before. The returned top 3 hot sentences should be sorted by hot degree (The first is the hottest one). If several sentences have the same degree of hot, you need to use ASCII-code order (smaller one appears first). If less than 3 hot sentences exist, then just return as many as you can. When the input is a special character, it means the sentence ends, and in this case, you need to return an empty list. Your job is to implement the following functions:
The constructor function:
AutocompleteSystem(String[] sentences, int[] times): This is the constructor. The input is historical data. Sentences is a string array consists of previously typed sentences. Times is the corresponding times a sentence has been typed. Your system should record these historical data.
Now, the user wants to input a new sentence. The following function will provide the next character the user types:
List
Example:
Operation: AutocompleteSystem(["i love you", "island","ironman", "i love leetcode"], [5,3,2,2])
The system have already tracked down the following sentences and their corresponding times:
"i love you" : 5 times
"island" : 3 times
"ironman" : 2 times
"i love leetcode" : 2 times
Now, the user begins another search:
Operation: input('i')
Output: ["i love you", "island","i love leetcode"]
Explanation:
There are four sentences that have prefix "i". Among them, "ironman" and "i love leetcode" have same hot degree. Since ' ' has ASCII code 32 and 'r' has ASCII code 114, "i love leetcode" should be in front of "ironman". Also we only need to output top 3 hot sentences, so "ironman" will be ignored.
Operation: input(' ')
Output: ["i love you","i love leetcode"]
Explanation:
There are only two sentences that have prefix "i ".
Operation: input('a')
Output: []
Explanation:
There are no sentences that have prefix "i a".
Operation: input('#')
Output: []
Explanation:
The user finished the input, the sentence "i a" should be saved as a historical sentence in system. And the following input will be counted as a new search.
Note:
The input sentence will always start with a letter and end with ‘#’, and only one blank space will exist between two words. The number of complete sentences that to be searched won’t exceed 100. The length of each sentence including those in the historical data won’t exceed 100. Please use double-quote instead of single-quote when you write test cases even for a character input. Please remember to RESET your class variables declared in class AutocompleteSystem, as static/class variables are persisted across multiple test cases. Please see here for more details.
Solution
class AutocompleteSystem {
//same as Tier, but with a HashMap to count the following words count.
class Node{
HashMap<Character, Node> children;
HashMap<String, Integer> count;
boolean isWord;
public Node(){
children = new HashMap();
count = new HashMap();
isWord = false;
}
}
//Can be replaced by Map.Entry<String,Integer>
class Pair{
String s;
int c;
public Pair(String s, int c){
this.s = s;
this.c = c;
}
}
Node root;
//store the prefix all the time.
String prefix;
public AutocompleteSystem(String[] sentences, int[] times) {
root = new Node();
prefix = "";
//add all words in to the tier.
for(int i = 0; i<sentences.length;i++){
add(sentences[i], times[i]);
}
}
private void add(String s, int count){
Node cur = root;
for(char c: s.toCharArray()){
Node next = cur.children.get(c);
if(next == null){
next = new Node();
cur.children.put(c, next);
}
cur = next;
cur.count.put(s, cur.count.getOrDefault(s,0)+count);
}
cur.isWord = true;
}
public List<String> input(char c) {
//reset the prefix.
if(c == '#'){
//add into the tier before reset.
add(prefix, 1);
prefix = "";
return new ArrayList<String>();
}
prefix += c;
Node cur = root;
for(char cc: prefix.toCharArray()){
Node next = cur.children.get(cc);
if(next == null){
return new ArrayList<String>();
}
cur =next;
}
//find the last Node.
//create a pq that sorted by count, if it's a tire, use string compare.
PriorityQueue<Pair> pq = new PriorityQueue<>((s1,s2)->(s1.c==s2.c?s1.s.compareTo(s2.s):s2.c-s1.c));
//add all contents from count map into the pq.
for(String s: cur.count.keySet()){
pq.add(new Pair(s,cur.count.get(s)));
}switch
List<String> res = new ArrayList();
for(int i = 0;i<3&&!pq.isEmpty();i++){
res.add(pq.poll().s);
}
return res;
}
}
2020-02-22
430. Flatten a Multilevel Doubly Linked List
Description
You are given a doubly linked list which in addition to the next and previous pointers, it could have a child pointer, which may or may not point to a separate doubly linked list. These child lists may have one or more children of their own, and so on, to produce a multilevel data structure, as shown in the example below.
Flatten the list so that all the nodes appear in a single-level, doubly linked list. You are given the head of the first level of the list.
Example 1:
Input: head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] Output: [1,2,3,7,8,11,12,9,10,4,5,6] Explanation:
The multilevel linked list in the input is as follows:
After flattening the multilevel linked list it becomes:
Example 2:
Input: head = [1,2,null,3] Output: [1,3,2] Explanation:
The input multilevel linked list is as follows:
1—2—NULL | 3—NULL Example 3:
Input: head = [] Output: []
How multilevel linked list is represented in test case:
We use the multilevel linked list from Example 1 above:
1—2—3—4—5—6–NULL | 7—8—9—10–NULL | 11–12–NULL The serialization of each level is as follows:
[1,2,3,4,5,6,null] [7,8,9,10,null] [11,12,null] To serialize all levels together we will add nulls in each level to signify no node connects to the upper node of the previous level. The serialization becomes:
[1,2,3,4,5,6,null] [null,null,7,8,9,10,null] [null,11,12,null] Merging the serialization of each level and removing trailing nulls we obtain:
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
Constraints:
Number of Nodes will not exceed 1000. 1 <= Node.val <= 10^5
Main Idea
Use recursion, if the current node has a child, flatten all the nodes in the child, insert into between cur and curNext.
Solution
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
return helper(head);
}
private Node helper(Node head){
if(head == null){
return null;
}
Node cur = head;
while(cur != null){
if(cur.child == null){
cur = cur.next;
continue;
}
Node c = helper(cur.child);
Node curNext = cur.next;
cur.next = c;
c.prev = cur;
while(c.next!=null){
c = c.next;
}
c.next = curNext;
if(curNext != null){
curNext.prev = c;
}
cur.child = null;
cur = curNext;
}
return head;
}
}
2020-02-23
362. Design Hit Counter
Description
Design a hit counter which counts the number of hits received in the past 5 minutes.
Each function accepts a timestamp parameter (in seconds granularity) and you may assume that calls are being made to the system in chronological order (ie, the timestamp is monotonically increasing). You may assume that the earliest timestamp starts at 1.
It is possible that several hits arrive roughly at the same time.
Example:
HitCounter counter = new HitCounter();
// hit at timestamp 1. counter.hit(1);
// hit at timestamp 2. counter.hit(2);
// hit at timestamp 3. counter.hit(3);
// get hits at timestamp 4, should return 3. counter.getHits(4);
// hit at timestamp 300. counter.hit(300);
// get hits at timestamp 300, should return 4. counter.getHits(300);
// get hits at timestamp 301, should return 3. counter.getHits(301); Follow up: What if the number of hits per second could be very large? Does your design scale?
Main Idea
use two array to store, ont time and one count.
time is to ensure that the previous time will be eliminated.
should not update everytime write, that’s time consuming, instead, we only sum up all the hits that happend in the last five minutes, which means:
timestamp - time[i] < 300 –> happend in the last 300 secs.
Solution
import java.util.concurrent.atomic.AtomicIntegerArray;
class HitCounter {
//use this data structure to ensure the concurrent issue.
AtomicIntegerArray time;
AtomicIntegerArray hits;
/** Initialize your data structure here. */
public HitCounter() {
time = new AtomicIntegerArray(300);
hits = new AtomicIntegerArray(300);
}
/** Record a hit.
@param timestamp - The current timestamp (in seconds granularity). */
public void hit(int timestamp) {
int idx = timestamp % 300;
if(time.get(idx) != timestamp){
time.set(idx,timestamp);
hits.set(idx,1);
}else{
hits.getAndIncrement(idx);
}
}
/** Return the number of hits in the past 5 minutes.
@param timestamp - The current timestamp (in seconds granularity). */
public int getHits(int timestamp) {
int count = 0;
for(int i =0;i<300;i++){
if(timestamp - time.get(i) < 300){
count += hits.get(i);
}
}
return count;
}
}
/**
* Your HitCounter object will be instantiated and called as such:
* HitCounter obj = new HitCounter();
* obj.hit(timestamp);
* int param_2 = obj.getHits(timestamp);
*/
1057. Campus Bikes
Description
On a campus represented as a 2D grid, there are N workers and M bikes, with N <= M. Each worker and bike is a 2D coordinate on this grid.
Our goal is to assign a bike to each worker. Among the available bikes and workers, we choose the (worker, bike) pair with the shortest Manhattan distance between each other, and assign the bike to that worker. (If there are multiple (worker, bike) pairs with the same shortest Manhattan distance, we choose the pair with the smallest worker index; if there are multiple ways to do that, we choose the pair with the smallest bike index). We repeat this process until there are no available workers.
| The Manhattan distance between two points p1 and p2 is Manhattan(p1, p2) = | p1.x - p2.x | + | p1.y - p2.y | . |
Return a vector ans of length N, where ans[i] is the index (0-indexed) of the bike that the i-th worker is assigned to.
Example 1:

Input: workers = [[0,0],[2,1]], bikes = [[1,2],[3,3]] Output: [1,0] Explanation: Worker 1 grabs Bike 0 as they are closest (without ties), and Worker 0 is assigned Bike 1. So the output is [1, 0]. Example 2:

Input: workers = [[0,0],[1,1],[2,0]], bikes = [[1,0],[2,2],[2,1]] Output: [0,2,1] Explanation: Worker 0 grabs Bike 0 at first. Worker 1 and Worker 2 share the same distance to Bike 2, thus Worker 1 is assigned to Bike 2, and Worker 2 will take Bike 1. So the output is [0,2,1].
Note:
0 <= workers[i][j], bikes[i][j] < 1000 All worker and bike locations are distinct. 1 <= workers.length <= bikes.length <= 1000
Main Idea
since the longest distance is 2000, we can use a array with length 2001 to store all the pairs.
For each list of pairs with the same length, we sorted using Collections.sort() with defined comparator.
Solution
class Solution {
public int[] assignBikes(int[][] workers, int[][] bikes) {
List<int[]>[] dist = new List[2001];
//calculate all the possible pairs and put into a array length 2001.
for(int w = 0;w<workers.length;w++){
for(int b = 0; b<bikes.length;b++){
int len = calc(workers[w],bikes[b]);
if(dist[len]==null){
dist[len] = new ArrayList<int[]>();
}
dist[len].add(new int[]{w,b});
}
}
//need to keep track of the workers and bikes.
int[] assigned = new int[workers.length];
Arrays.fill(assigned,-1);
boolean[] used = new boolean[bikes.length];
for(int i = 0;i< dist.length;i++){
List<int[]> pairs = dist[i];
if(pairs == null) continue;
//sort based ont he rules.
Collections.sort(pairs,(p1,p2)->(p1[0]==p2[0]?p1[1]-p2[1]:p1[0]-p2[0]));
for(int j = 0;j<pairs.size();j++){
int[] pair = pairs.get(j);
//if already assigned, then skip.
if(assigned[pair[0]] == -1 && !used[pair[1]]){
assigned[pair[0]] = pair[1];
used[pair[1]] = true;
}
}
}
return assigned;
}
private int calc(int[] p1, int[] p2){
return Math.abs(p1[0]-p2[0]) + Math.abs(p1[1]-p2[1]);
}
}
222. Count Complete Tree Nodes
Description
Given a complete binary tree, count the number of nodes.
Note:
Definition of a complete binary tree from Wikipedia: In a complete binary tree every level, except possibly the last, is completely filled, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.
Example:
Input:
1
/ \
2 3
/ \ /
4 5 6
Output: 6
Main Idea
use left most height as the height of the tree.
if h(left) == h(right), means right subtree’s last layer is not empty, then we don’t have to calc left tree, only need to calc the right.
if h(left) == h(right) + 1 means last layer of right tree is empty. So we just need to calc left tree.
Solution
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
if(root == null) return 0;
int leftH = height(root.left);
int rightH = height(root.right);
if(rightH == leftH){
//last layer of right tree is not empty. only need to calc right tree.
return (1<<rightH) + countNodes(root.right);
}else{
//last layer of right tree is empty. just need to calc left tree.
return (1 <<rightH) + countNodes(root.left);
}
}
private int height(TreeNode root){
int count = 0;
while(root != null){
root = root.left;
count++;
}
return count;
}
}
359. Logger Rate Limiter
Description
Design a logger system that receive stream of messages along with its timestamps, each message should be printed if and only if it is not printed in the last 10 seconds.
Given a message and a timestamp (in seconds granularity), return true if the message should be printed in the given timestamp, otherwise returns false.
It is possible that several messages arrive roughly at the same time.
Example:
Logger logger = new Logger();
// logging string “foo” at timestamp 1 logger.shouldPrintMessage(1, “foo”); returns true;
// logging string “bar” at timestamp 2 logger.shouldPrintMessage(2,”bar”); returns true;
// logging string “foo” at timestamp 3 logger.shouldPrintMessage(3,”foo”); returns false;
// logging string “bar” at timestamp 8 logger.shouldPrintMessage(8,”bar”); returns false;
// logging string “foo” at timestamp 10 logger.shouldPrintMessage(10,”foo”); returns false;
// logging string “foo” at timestamp 11 logger.shouldPrintMessage(11,”foo”); returns true;
Solution
class Logger {
int[] time;
Set<String>[] hits;
/** Initialize your data structure here. */
public Logger() {
time = new int[10];
hits = new HashSet[10];
//need to fill and initialize.
Arrays.fill(hits,new HashSet<String>());
}
/** Returns true if the message should be printed in the given timestamp, otherwise returns false.
If this method returns false, the message will not be printed.
The timestamp is in seconds granularity. */
public boolean shouldPrintMessage(int timestamp, String message) {
int idx = timestamp % 10;
for(int i = 0;i<10;i++){
//check all printed words in the last 10 secs. if printed, just return false;
if(timestamp - time[i]<10 && hits[i]!=null && hits[i].contains(message)){
return false;
}
}
//failed to find word in the last 10 second, then will print this time.
//update all the data. if this is the first time we reached this time point, we need to erase all the previous messgae.
if(time[idx] != timestamp){
time[idx] = timestamp;
hits[idx] = new HashSet();
}
//add it to set.
hits[idx].add(message);
return true;
}
}
/**
* Your Logger object will be instantiated and called as such:
* Logger obj = new Logger();
* boolean param_1 = obj.shouldPrintMessage(timestamp,message);
*/
Road
路路无相似,山山皆不同。
人人万般苦,苦苦皆不尽。
1055. Shortest Way to Form String
Description
From any string, we can form a subsequence of that string by deleting some number of characters (possibly no deletions).
Given two strings source and target, return the minimum number of subsequences of source such that their concatenation equals target. If the task is impossible, return -1.
Example 1:
Input: source = “abc”, target = “abcbc” Output: 2 Explanation: The target “abcbc” can be formed by “abc” and “bc”, which are subsequences of source “abc”. Example 2:
Input: source = “abc”, target = “acdbc” Output: -1 Explanation: The target string cannot be constructed from the subsequences of source string due to the character “d” in target string. Example 3:
Input: source = “xyz”, target = “xzyxz” Output: 3 Explanation: The target string can be constructed as follows “xz” + “y” + “xz”.
Constraints:
Both the source and target strings consist of only lowercase English letters from “a”-“z”. The lengths of source and target string are between 1 and 1000.
Solution
class Solution {
public int shortestWay(String source, String target) {
char[] s = source.toCharArray();
char[] t = target.toCharArray();
int count = 0;
//no need to increment by 1, would be easiler if we loop the source entirly once, and then increment i accordingly.
for(int i = 0;i<t.length;){
//need to compare if i increment, if not, means target has a char that does not exist in the source, so return -1.
int preI = i;
//iterate the whole source.
for(int j = 0;j<s.length;j++){
if(i<t.length && t[i]==s[j]){
i++;
}
}
if(preI == i) return -1;
//an entire iteration of source.
count++;
}
return count;
}
}
593. Valid Square
Description
Given the coordinates of four points in 2D space, return whether the four points could construct a square.
The coordinate (x,y) of a point is represented by an integer array with two integers.
Example:
Input: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,1] Output: True
Note:
All the input integers are in the range [-10000, 10000]. A valid square has four equal sides with positive length and four equal angles (90-degree angles). Input points have no order.
Solution
class Solution {
public boolean validSquare(int[] p1, int[] p2, int[] p3, int[] p4) {
int[][] points = new int[4][2];
points[0] = p1;
points[1] = p2;
points[2] = p3;
points[3] = p4;
Arrays.sort(points,(o1,o2)->(o1[0]==o2[0]?o1[1]-o2[1]:o1[0]-o2[0]));
if(dist(points[0],points[3]) == dist(points[1],points[2])
&& dist(points[0],points[1])==dist(points[0],points[2])
&& points[0][0]!=points[3][0]) return true;
return false;
}
private int dist(int[]p1, int[] p2){
return (p1[0]-p2[0])*(p1[0]-p2[0]) + (p1[1]-p2[1])*(p1[1]-p2[1]);
}
}
public boolean validSquare(int[] p1, int[] p2, int[] p3, int[] p4) {
long[] lengths = {length(p1, p2), length(p2, p3), length(p3, p4),
length(p4, p1), length(p1, p3),length(p2, p4)}; // all 6 sides
long max = 0, nonMax = 0;
for(long len : lengths) {
max = Math.max(max, len);
}
int count = 0;
for(int i = 0; i < lengths.length; i++) {
if(lengths[i] == max) count++;
else nonMax = lengths[i]; // non diagonal side.
}
if(count != 2) return false; // diagonals lenghts have to be same.
for(long len : lengths) {
if(len != max && len != nonMax) return false; // sides have to be same length
}
return true;
}
2020-02-24
1197. Minimum Knight Moves
Description
In an infinite chess board with coordinates from -infinity to +infinity, you have a knight at square [0, 0].
A knight has 8 possible moves it can make, as illustrated below. Each move is two squares in a cardinal direction, then one square in an orthogonal direction.
Return the minimum number of steps needed to move the knight to the square [x, y]. It is guaranteed the answer exists.

Example 1:
Input: x = 2, y = 1 Output: 1 Explanation: [0, 0] → [2, 1] Example 2:
Input: x = 5, y = 5 Output: 4 Explanation: [0, 0] → [2, 1] → [4, 2] → [3, 4] → [5, 5]
Constraints:
| x | + | y | <= 300 |
Main Idea
Solution
class Solution {
HashSet<String> reached;
int[][] dirs = new int[][][[1,2],[1,-2],[2,1],[2,-1],[-1,2],[-1,-2],[-2,1],[-2,-1]];
public int minKnightMoves(int x, int y) {
x = Math.abs(x);
y = Math.abs(y);
String target = x + "*" + y;
reached = new HashSet();
Queue<int[]> q = new LinkedList();
q.add(new int[]{0,0});
int count = 0;
reached.add(0+"*"+0);
while(!q.isEmpty()){
int size = q.size();
for(int j = 0;j<size;j++){
int[] cur = q.poll();
if(cur[0] == x && cur[1] == y){
return count;
}
for(int i = 0;i<8;i++){
int newX = cur[0] + dirs[i][0];
int newY = cur[1] + dirs[i][1];
String temp = newX + "*" + newY;
if(!reached.contains(temp) && newX >= -1 && newY >= -1){
reached.add(temp);
q.add(new int[]{newX,newY});
}
}
}
count++;
}
return -1;
}
}
1011. Capacity To Ship Packages Within D Days
Description
A conveyor belt has packages that must be shipped from one port to another within D days.
The i-th package on the conveyor belt has a weight of weights[i]. Each day, we load the ship with packages on the conveyor belt (in the order given by weights). We may not load more weight than the maximum weight capacity of the ship.
Return the least weight capacity of the ship that will result in all the packages on the conveyor belt being shipped within D days.
Example 1:
Input: weights = [1,2,3,4,5,6,7,8,9,10], D = 5 Output: 15 Explanation: A ship capacity of 15 is the minimum to ship all the packages in 5 days like this: 1st day: 1, 2, 3, 4, 5 2nd day: 6, 7 3rd day: 8 4th day: 9 5th day: 10
Note that the cargo must be shipped in the order given, so using a ship of capacity 14 and splitting the packages into parts like (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) is not allowed. Example 2:
Input: weights = [3,2,2,4,1,4], D = 3 Output: 6 Explanation: A ship capacity of 6 is the minimum to ship all the packages in 3 days like this: 1st day: 3, 2 2nd day: 2, 4 3rd day: 1, 4 Example 3:
Input: weights = [1,2,3,1,1], D = 4 Output: 3 Explanation: 1st day: 1 2nd day: 2 3rd day: 3 4th day: 1, 1
Note:
1 <= D <= weights.length <= 50000 1 <= weights[i] <= 500
Solution
//same question as coco eats banana.
class Solution {
public int shipWithinDays(int[] weights, int D) {
int left = 0;
int right = 0;
for(int w:weights){
left = Math.max(left, w);
right += w;
}
while(left < right){
int mid = (left + right) / 2;
if(!canShip(weights,mid,D)){
left = mid + 1;
}else{
right = mid;
}
}
return left;
}
private boolean canShip(int[] weights, int capacity, int day){
int count = 1;
int curW = 0;
for(int w : weights){
if(curW + w > capacity){
curW = 0;
count++;
}
curW += w;
}
return count <= day;
}
}
1110. Delete Nodes And Return Forest
Description
Given the root of a binary tree, each node in the tree has a distinct value.
After deleting all nodes with a value in to_delete, we are left with a forest (a disjoint union of trees).
Return the roots of the trees in the remaining forest. You may return the result in any order.
Example 1:
Input: root = [1,2,3,4,5,6,7], to_delete = [3,5] Output: [[1,2,null,4],[6],[7]]
Constraints:
The number of nodes in the given tree is at most 1000. Each node has a distinct value between 1 and 1000. to_delete.length <= 1000 to_delete contains distinct values between 1 and 1000.
Solution
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
HashSet<Integer> toDelete;
List<TreeNode> res;
public List<TreeNode> delNodes(TreeNode root, int[] to_delete) {
toDelete = new HashSet();
res = new ArrayList<TreeNode>();
for(int n : to_delete){
toDelete.add(n);
}
if(!toDelete.contains(root.val)) res.add(root);
helper(root);
return res;
}
private TreeNode helper(TreeNode root){
if(root == null) return null;
root.left = helper(root.left);
root.right = helper(root.right);
//if the root is going to be deleted:
//add it's child, which is already processed, into the res.
//return null, so it's parent will lose it as a child.
if(toDelete.contains(root.val)){
if(root.left != null) res.add(root.left);
if(root.right != null) res.add(root.right);
return null;
}
//if it's not deleted, then append to it's parent.
return root;
}
}
939. Minimum Area Rectangle
Description
Given a set of points in the xy-plane, determine the minimum area of a rectangle formed from these points, with sides parallel to the x and y axes.
If there isn’t any rectangle, return 0.
Example 1:
Input: [[1,1],[1,3],[3,1],[3,3],[2,2]]
Output: 4
Example 2:
Input: [[1,1],[1,3],[3,1],[3,3],[4,1],[4,3]]
Output: 2
Note:
1 <= points.length <= 500
0 <= points[i][0] <= 40000
0 <= points[i][1] <= 40000
All points are distinct.
Solution
class Solution {
public int minAreaRect(int[][] points) {
Map<Integer,Set<Integer>> map = new HashMap();
//collect all points and group by x.
for(int[] p : points){
if(!map.containsKey(p[0])){
map.put(p[0],new HashSet<Integer>());
}
map.get(p[0]).add(p[1]);
}
int res = Integer.MAX_VALUE;
//improvement: no need for second point to start from 0, cause p1 already searched combination (p1,p2) where p2<i
for(int i = 0; i<points.length;i++){
for(int j = i+1;j<points.length;j++){
int[] p1 = points[i];
int[] p2 = points[j];
//we are only looking for points on diagnal, if paralle to x or y axie, skip.
if(p1[0]==p2[0] || p1[1]==p2[1]){
continue;
}
//calc area of this rectangle.
if(map.get(p1[0]).contains(p2[1]) && map.get(p2[0]).contains(p1[1])){
res = Math.min(res, Math.abs(p1[0]-p2[0]) * Math.abs(p1[1]-p2[1]));
}
}
}
//if unable to find, res should be unchanged.
return res == Integer.MAX_VALUE? 0: res;
}
}
809. Expressive Words
Description
Sometimes people repeat letters to represent extra feeling, such as “hello” -> “heeellooo”, “hi” -> “hiiii”. In these strings like “heeellooo”, we have groups of adjacent letters that are all the same: “h”, “eee”, “ll”, “ooo”.
For some given string S, a query word is stretchy if it can be made to be equal to S by any number of applications of the following extension operation: choose a group consisting of characters c, and add some number of characters c to the group so that the size of the group is 3 or more.
For example, starting with “hello”, we could do an extension on the group “o” to get “hellooo”, but we cannot get “helloo” since the group “oo” has size less than 3. Also, we could do another extension like “ll” -> “lllll” to get “helllllooo”. If S = “helllllooo”, then the query word “hello” would be stretchy because of these two extension operations: query = “hello” -> “hellooo” -> “helllllooo” = S.
Given a list of query words, return the number of words that are stretchy.
Example:
Input:
S = "heeellooo"
words = ["hello", "hi", "helo"]
Output: 1
Explanation:
We can extend "e" and "o" in the word "hello" to get "heeellooo".
We can't extend "helo" to get "heeellooo" because the group "ll" is not size 3 or more.
Notes:
0 <= len(S) <= 100. 0 <= len(words) <= 100. 0 <= len(words[i]) <= 100. S and all words in words consist only of lowercase letters
Solution
class Solution {
public int expressiveWords(String S, String[] words) {
int count = 0;
char[] target = S.toCharArray();
for(String word : words){
if(isStrachy(target, word.toCharArray())){
count++;
}
}
return count;
}
private boolean isStrachy(char[] target, char[] source){
int tl = 0, tr = 0, sl = 0,sr = 0;
int tLen = target.length, sLen = source.length;
//count the number of the group.
while(tl<tLen && sl<sLen){
if(target[tl] != source[sl]) return false;
int tCount = 0, sCount = 0;
//left tr go through to the end of the group;
while(tr < tLen && target[tr]==target[tl]){
tr++;
tCount++;
}
while(sr < sLen && source[sr] == source[sl]){
sr++;
sCount++;
}
//if source has more char than target, invalid. No remove action.
if(sCount > tCount) return false;
//if they have the same amount of char, valid.
//otherwise the target Count is less than 3, invalid.
if(sCount != tCount && tCount < 3) return false;
tl = tr;
sl = sr;
}
//if either pointer does not reach the end, means there's a character does not exist in the source but in the target.
return (tl==tLen && sl==sLen)?true:false;
}
}
2020-02-25
299. Bulls and Cows
Description
You are playing the following Bulls and Cows game with your friend: You write down a number and ask your friend to guess what the number is. Each time your friend makes a guess, you provide a hint that indicates how many digits in said guess match your secret number exactly in both digit and position (called “bulls”) and how many digits match the secret number but locate in the wrong position (called “cows”). Your friend will use successive guesses and hints to eventually derive the secret number.
Write a function to return a hint according to the secret number and friend’s guess, use A to indicate the bulls and B to indicate the cows.
Please note that both secret number and friend’s guess may contain duplicate digits.
Example 1:
Input: secret = "1807", guess = "7810"
Output: "1A3B"
Explanation: 1 bull and 3 cows. The bull is 8, the cows are 0, 1 and 7.
Example 2:
Input: secret = "1123", guess = "0111"
Output: "1A1B"
Explanation: The 1st 1 in friend's guess is a bull, the 2nd or 3rd 1 is a cow.
Note: You may assume that the secret number and your friend's guess only contain digits, and their lengths are always equal.
Solution
class Solution {
public String getHint(String secret, String guess) {
int bull = 0;
int cow = 0;
HashMap<Integer,Integer> map = new HashMap();
for(int i = 0; i<secret.length();i++){
int s = secret.charAt(i)-'0';
if(s == guess.charAt(i)-'0') bull++;
map.put(s,map.getOrDefault(s,0)+1);
}
for(int i = 0; i<secret.length();i++){
int g = guess.charAt(i) - '0';
if(map.containsKey(g) && map.get(g)>0){
cow++;
map.put(g,map.get(g)-1);
}
}
cow -= bull;
return bull + "A" + cow +"B";
}
}
1170. Compare Strings by Frequency of the Smallest Character
Description
Let’s define a function f(s) over a non-empty string s, which calculates the frequency of the smallest character in s. For example, if s = “dcce” then f(s) = 2 because the smallest character is “c” and its frequency is 2.
Now, given string arrays queries and words, return an integer array answer, where each answer[i] is the number of words such that f(queries[i]) < f(W), where W is a word in words.
Example 1:
Input: queries = ["cbd"], words = ["zaaaz"]
Output: [1]
Explanation: On the first query we have f("cbd") = 1, f("zaaaz") = 3 so f("cbd") < f("zaaaz").
Example 2:
Input: queries = ["bbb","cc"], words = ["a","aa","aaa","aaaa"]
Output: [1,2]
Explanation: On the first query only f("bbb") < f("aaaa"). On the second query both f("aaa") and f("aaaa") are both > f("cc").
Constraints:
1 <= queries.length <= 2000 1 <= words.length <= 2000 1 <= queries[i].length, words[i].length <= 10 queries[i][j], words[i][j] are English lowercase letters.
Solution
class Solution {
public int[] numSmallerByFrequency(String[] queries, String[] words) {
double[] wordsCount = new double[words.length];
int[] qCount = new int[queries.length];
for(int i = 0;i<words.length;i++){
wordsCount[i] = (double)f(words[i]);
}
for(int i = 0;i<queries.length;i++){
qCount[i] = f(queries[i]);
}
Arrays.sort(wordsCount);
int[] res = new int[queries.length];
for(int i = 0;i<queries.length;i++){
int idx = Arrays.binarySearch(wordsCount,qCount[i]+.5);
res[i] = words.length + (idx + 1);
}
return res;
}
private int f(String word){
int[] count = new int[26];
for(char c : word.toCharArray()){
count[c-'a']++;
}
for(int i = 0;i<26;i++){
if(count[i]>0){
return count[i];
}
}
return 0;
}
}
2020-02-26
889. Construct Binary Tree from Preorder and Postorder Traversal
Description
Return any binary tree that matches the given preorder and postorder traversals.
Values in the traversals pre and post are distinct positive integers.
Example 1:
Input: pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1] Output: [1,2,3,4,5,6,7]
Note:
1 <= pre.length == post.length <= 30 pre[] and post[] are both permutations of 1, 2, …, pre.length. It is guaranteed an answer exists. If there exists multiple answers, you can return any of them.
Solution
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
HashMap<Integer, Integer> map;
public TreeNode constructFromPrePost(int[] pre, int[] post) {
map = new HashMap();
for(int i= 0;i<post.length;i++){
map.put(post[i],i);
}
return helper(0,pre.length-1,0,pre.length-1,pre,post);
}
private TreeNode helper(int preLeft, int preRight, int postLeft, int postRight, int[] pre, int[] post){
if(preLeft > preRight || postLeft > postRight){
return null;
}
TreeNode root = new TreeNode(pre[preLeft++]);
//System.out.println(preLeft + " " + preRight + " " +postLeft + " " +postRight);
if(preLeft <= preRight){
int postIdx = map.get(pre[preLeft]);
int sum = postIdx - postLeft + 1;
root.left = helper(preLeft, preLeft + sum - 1, postLeft, postIdx, pre, post);
//why not use root.right = helper(preRight - sum + 1, preRight, postRight - sum, postRight - 1,pre, post);
//root.right might be null, so we should not use preRight-sum but instead preLeft+sum so it can be invalid and return null.
root.right = helper(preLeft + sum, preRight, postLeft + sum, postRight - 1,pre, post);
}
return root;
}
}
752. Open the Lock
Description
You have a lock in front of you with 4 circular wheels. Each wheel has 10 slots: ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’. The wheels can rotate freely and wrap around: for example we can turn ‘9’ to be ‘0’, or ‘0’ to be ‘9’. Each move consists of turning one wheel one slot.
The lock initially starts at ‘0000’, a string representing the state of the 4 wheels.
You are given a list of deadends dead ends, meaning if the lock displays any of these codes, the wheels of the lock will stop turning and you will be unable to open it.
Given a target representing the value of the wheels that will unlock the lock, return the minimum total number of turns required to open the lock, or -1 if it is impossible.
Example 1:
Input: deadends = ["0201","0101","0102","1212","2002"], target = "0202"
Output: 6
Explanation:
A sequence of valid moves would be "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202".
Note that a sequence like "0000" -> "0001" -> "0002" -> "0102" -> "0202" would be invalid,
because the wheels of the lock become stuck after the display becomes the dead end "0102".
Example 2:
Input: deadends = ["8888"], target = "0009"
Output: 1
Explanation:
We can turn the last wheel in reverse to move from "0000" -> "0009".
Example 3:
Input: deadends = ["8887","8889","8878","8898","8788","8988","7888","9888"], target = "8888"
Output: -1
Explanation:
We can't reach the target without getting stuck.
Example 4:
Input: deadends = ["0000"], target = "8888"
Output: -1
Note:
The length of deadends will be in the range [1, 500].
target will not be in the list deadends.
Every string in deadends and the string target will be a string of 4 digits from the 10,000 possibilities '0000' to '9999'.
Solution
class Solution {
public int openLock(String[] deadends, String target) {
HashSet<String> reached = new HashSet();
for(String s:deadends){
reached.add(s);
}
final String start = "0000";
Queue<String> q = new LinkedList();
if(!reached.contains(start)){
q.add(start);
}
reached.add(start);
int count = 0;
while(!q.isEmpty()){
int size = q.size();
for(int i = 0;i<size;i++){
String cur = q.poll();
if(target.equals(cur)) return count;
for(int j = 0;j<4;j++){
char c = cur.charAt(j);
String add_str = cur.substring(0,j) +(c=='9'?0:c+1-'0')+cur.substring(j+1);
String sub_str = cur.substring(0,j) +(c=='0'?9:c-1-'0')+cur.substring(j+1);
if(!reached.contains(add_str)){
q.add(add_str);
reached.add(add_str);
}
if(!reached.contains(sub_str)){
q.add(sub_str);
reached.add(sub_str);
}
}
}
count++;
}
return -1;
}
}
//use two sets and reached from 2-side, and switch so we always search the smaller set.
class Solution {
public int openLock(String[] deadends, String target) {
final String start = "0000";
HashSet<String> begin = new HashSet();
HashSet<String> end = new HashSet();
HashSet<String> temp = new HashSet();
HashSet<String> reached = new HashSet<>(Arrays.asList(deadends));
begin.add(start);
end.add(target);
int count = 0;
while(!begin.isEmpty() && !end.isEmpty()){
if(begin.size() > end.size()){
temp = begin;
begin = end;
end = temp;
}
temp = new HashSet();
for(String cur : begin){
if(end.contains(cur)) return count;
if(reached.contains(cur)) continue;
//only add to reached after actually visited.
//unlike the previous solution where add to reached before add to queue.
reached.add(cur);
for(int j = 0;j<4;j++){
char c = cur.charAt(j);
String add_str = cur.substring(0,j) +(c=='9'?0:c+1-'0')+cur.substring(j+1);
String sub_str = cur.substring(0,j) +(c=='0'?9:c-1-'0')+cur.substring(j+1);
if(!reached.contains(add_str)){
temp.add(add_str);
}
if(!reached.contains(sub_str)){
temp.add(sub_str);
}
}
}
count++;
begin = temp;
}
return -1;
}
}
1146. Snapshot Array
Description
Implement a SnapshotArray that supports the following interface:
SnapshotArray(int length) initializes an array-like data structure with the given length. Initially, each element equals 0. void set(index, val) sets the element at the given index to be equal to val. int snap() takes a snapshot of the array and returns the snap_id: the total number of times we called snap() minus 1. int get(index, snap_id) returns the value at the given index, at the time we took the snapshot with the given snap_id
Example 1:
Input: ["SnapshotArray","set","snap","set","get"]
[[3],[0,5],[],[0,6],[0,0]]
Output: [null,null,0,null,5]
Explanation:
SnapshotArray snapshotArr = new SnapshotArray(3); // set the length to be 3
snapshotArr.set(0,5); // Set array[0] = 5
snapshotArr.snap(); // Take a snapshot, return snap_id = 0
snapshotArr.set(0,6);
snapshotArr.get(0,0); // Get the value of array[0] with snap_id = 0, return 5
Constraints:
1 <= length <= 50000 At most 50000 calls will be made to set, snap, and get. 0 <= index < length 0 <= snap_id < (the total number of times we call snap()) 0 <= val <= 10^9
Solution
class SnapshotArray {
TreeMap<Integer, Integer>[] A;
int snap_id = 0;
public SnapshotArray(int length) {
A = new TreeMap[length];
for(int i = 0; i<length;i++){
A[i] = new TreeMap<Integer,Integer>();
A[i].put(0,0);
}
}
public void set(int index, int val) {
A[index].put(snap_id, val);
}
public int snap() {
return snap_id++;
}
//TreeMap allows: ceilingEntry & floorEntry!
public int get(int index, int snap_id) {
return A[index].floorEntry(snap_id).getValue();
}
}
/**
* Your SnapshotArray object will be instantiated and called as such:
* SnapshotArray obj = new SnapshotArray(length);
* obj.set(index,val);
* int param_2 = obj.snap();
* int param_3 = obj.get(index,snap_id);
*/
class SnapshotArray {
List<int[]>[] record;
int sid;
public SnapshotArray(int length) {
record = new List[length];
sid = 0;
for (int i = 0; i < length; i++) {
record[i] = new ArrayList<>();
record[i].add(new int[]{0, 0});
}
}
public void set(int index, int val) {
if (record[index].get(record[index].size() - 1)[0] == sid) {
record[index].get(record[index].size() - 1)[1] = val;
} else
record[index].add(new int[]{sid, val});
}
public int snap() {
return sid++;
}
public int get(int index, int snap_id) {
int idx = Collections.binarySearch(record[index], new int[]{snap_id, 0},
(a, b) -> Integer.compare(a[0], b[0]));
if (idx < 0) idx = - idx - 2;
return record[index].get(idx)[1];
}
}
1219. Path with Maximum Gold
Description
In a gold mine grid of size m * n, each cell in this mine has an integer representing the amount of gold in that cell, 0 if it is empty.
Return the maximum amount of gold you can collect under the conditions:
Every time you are located in a cell you will collect all the gold in that cell. From your position you can walk one step to the left, right, up or down. You can’t visit the same cell more than once. Never visit a cell with 0 gold. You can start and stop collecting gold from any position in the grid that has some gold.
Example 1:
Input: grid = [[0,6,0],[5,8,7],[0,9,0]]
Output: 24
Explanation:
[[0,6,0],
[5,8,7],
[0,9,0]]
Path to get the maximum gold, 9 -> 8 -> 7.
Example 2:
Input: grid = [[1,0,7],[2,0,6],[3,4,5],[0,3,0],[9,0,20]]
Output: 28
Explanation:
[[1,0,7],
[2,0,6],
[3,4,5],
[0,3,0],
[9,0,20]]
Path to get the maximum gold, 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7.
Constraints:
1 <= grid.length, grid[i].length <= 15 0 <= grid[i][j] <= 100 There are at most 25 cells containing gold.
Solution
class Solution {
int[][] dirs = new int[][][[0,-1],[0,1],[-1,0],[1,0]];
public int getMaximumGold(int[][] grid) {
int max_val = 0;
for(int y = 0;y<grid.length;y++){
for(int x = 0;x<grid[0].length;x++){
//try to start from any point to max the sum of gold.
max_val = Math.max(max_val,helper(grid,x,y));
}
}
return max_val;
}
private int helper(int[][] grid, int x, int y){
//no where else to go and will return 0;
//boarder, visited, empty.
if(y < 0 || x<0|| y>=grid.length||x>=grid[y].length||grid[y][x] <= 0)
return 0;
//no need to use an extra hashset to store the reached point, just revert it.
grid[y][x] = -grid[y][x];
int val = 0;
for(int[] dir : dirs){
int newX = x + dir[0];
int newY = y + dir[1];
val = Math.max(val,helper(grid, newX,newY));
}
//unmark it for next loop.
grid[y][x] = -grid[y][x];
return val+grid[y][x];
}
}
2020-02-27
659. Split Array into Consecutive Subsequences
Description
Given an array nums sorted in ascending order, return true if and only if you can split it into 1 or more subsequences such that each subsequence consists of consecutive integers and has length at least 3.
Example 1:
Input: [1,2,3,3,4,5]
Output: True
Explanation:
You can split them into two consecutive subsequences :
1, 2, 3
3, 4, 5
Example 2:
Input: [1,2,3,3,4,4,5,5]
Output: True
Explanation:
You can split them into two consecutive subsequences :
1, 2, 3, 4, 5
3, 4, 5
Example 3:
Input: [1,2,3,4,4,5]
Output: False
Constraints:
1 <= nums.length <= 10000
Solution
class Solution {
public boolean isPossible(int[] nums) {
//count the number.
HashMap<Integer, Integer> freq = new HashMap();
//store the tail of the subsequence.
HashMap<Integer, Integer> appendfreq = new HashMap();
for(int n:nums){
freq.put(n,freq.getOrDefault(n,0)+1);
}
//should try to append first, then try to create a new subsequence.
//1 2 3 4 5 5 6 7 will fail if reversed.
for(int n: nums){
if(freq.get(n)==0) continue;
//if there is a valid subsequence, append to it.
if(appendfreq.getOrDefault(n,0)>0){
appendfreq.put(n,appendfreq.get(n)-1);
appendfreq.put(n+1,appendfreq.getOrDefault(n+1,0)+1);
}else if(freq.getOrDefault(n+1,0)>0 && freq.getOrDefault(n+2,0)>0){
//if no valid subsequence, create one.
appendfreq.put(n+3, appendfreq.getOrDefault(n+3,0)+1);
freq.put(n+1,freq.get(n+1)-1);
freq.put(n+2,freq.get(n+2)-1);
}else{
//if this num is NO WHERE TO GO, means it's not possible.
return false;
}
freq.put(n,freq.get(n)-1);
}
return true;
}
}
271. Encode and Decode Strings
Description
Design an algorithm to encode a list of strings to a string. The encoded string is then sent over the network and is decoded back to the original list of strings.
Machine 1 (sender) has the function:
string encode(vector<string> strs) {
// ... your code
return encoded_string;
}
Machine 2 (receiver) has the function:
vector<string> decode(string s) {
//... your code
return strs;
}
So Machine 1 does:
string encoded_string = encode(strs);
and Machine 2 does:
vector<string> strs2 = decode(encoded_string);
strs2 in Machine 2 should be the same as strs in Machine 1.
Implement the encode and decode methods.
Note:
The string may contain any possible characters out of 256 valid ascii characters. Your algorithm should be generalized enough to work on any possible characters. Do not use class member/global/static variables to store states. Your encode and decode algorithms should be stateless. Do not rely on any library method such as eval or serialize methods. You should implement your own encode/decode algorithm.
Solution
//no matter what spliter we choose, it's okay since we record the length of the string, we will skip the spliter in the actual string.
public class Codec {
final String split = "/";
// Encodes a list of strings to a single string.
public String encode(List<String> strs) {
StringBuilder sb = new StringBuilder();
for(String str: strs){
sb.append(str.length()).append(split).append(str);
}
return sb.toString();
}
// Decodes a single string to a list of strings.
public List<String> decode(String s) {
List<String> res = new ArrayList();
int i = 0;
while(i<s.length()){
//find the index of the first spliter starting from index i.
int sIdx = s.indexOf(split,i);
//parse int and find the length of the string.
int size = Integer.parseInt(s.substring(i,sIdx));
i = sIdx + size + 1;
//substring and get the actual string.
String cur = s.substring(sIdx+1,i);
res.add(cur);
}
return res;
}
}
// Your Codec object will be instantiated and called as such:
// Codec codec = new Codec();
// codec.decode(codec.encode(strs));
482. License Key Formatting
Description
You are given a license key represented as a string S which consists only alphanumeric character and dashes. The string is separated into N+1 groups by N dashes.
Given a number K, we would want to reformat the strings such that each group contains exactly K characters, except for the first group which could be shorter than K, but still must contain at least one character. Furthermore, there must be a dash inserted between two groups and all lowercase letters should be converted to uppercase.
Given a non-empty string S and a number K, format the string according to the rules described above.
Example 1:
Input: S = "5F3Z-2e-9-w", K = 4
Output: "5F3Z-2E9W"
Explanation: The string S has been split into two parts, each part has 4 characters.
Note that the two extra dashes are not needed and can be removed.
Example 2:
Input: S = "2-5g-3-J", K = 2
Output: "2-5G-3J"
Explanation: The string S has been split into three parts, each part has 2 characters except the first part as it could be shorter as mentioned above.
Note:
The length of string S will not exceed 12,000, and K is a positive integer.
String S consists only of alphanumerical characters (a-z and/or A-Z and/or 0-9) and dashes(-).
String S is non-empty.
Solution
class Solution {
public String licenseKeyFormatting(String S, int K) {
S = S.replace("-","").toUpperCase();
int len = S.length();
int i = len-1;
StringBuilder sb = new StringBuilder();
while(i>=0){
for(int j=K;j>0 && i>=0;j--,i--){
sb.append(S.charAt(i));
}
if(i>=0){
sb.append("-");
}
}
return sb.reverse().toString();
}
}
846. Hand of Straights
Description
Alice has a hand of cards, given as an array of integers.
Now she wants to rearrange the cards into groups so that each group is size W, and consists of W consecutive cards.
Return true if and only if she can.
Example 1:
Input: hand = [1,2,3,6,2,3,4,7,8], W = 3
Output: true
Explanation: Alice's hand can be rearranged as [1,2,3],[2,3,4],[6,7,8].
Example 2:
Input: hand = [1,2,3,4,5], W = 4
Output: false
Explanation: Alice's hand can't be rearranged into groups of 4.
Note:
1 <= hand.length <= 10000 0 <= hand[i] <= 10^9 1 <= W <= hand.length
Solution
class Solution {
public boolean isNStraightHand(int[] hand, int W) {
int len = hand.length;
Arrays.sort(hand);
HashMap<Integer,Integer> freq = new HashMap();
for(int n: hand){
freq.put(n, freq.getOrDefault(n, 0)+ 1);
}
for(int n:hand){
if(freq.get(n)==0){
continue;
}
//find if current number can form a continuious subsequence.
//otherwise this num will have no where else to go.
for(int i=0;i<W;i++){
int cur = n + i;
if(freq.getOrDefault(cur,0)>0){
freq.put(cur, freq.get(cur)-1);
}else{
return false;
}
}
}
return true;
}
}
743. Network Delay Time
Description
There are N network nodes, labelled 1 to N.
Given times, a list of travel times as directed edges times[i] = (u, v, w), where u is the source node, v is the target node, and w is the time it takes for a signal to travel from source to target.
Now, we send a signal from a certain node K. How long will it take for all nodes to receive the signal? If it is impossible, return -1.
Example 1:

Input: times = [[2,1,1],[2,3,1],[3,4,1]], N = 4, K = 2
Output: 2
Note:
N will be in the range [1, 100].
K will be in the range [1, N].
The length of times will be in the range [1, 6000].
All edges times[i] = (u, v, w) will have 1 <= u, v <= N and 0 <= w <= 100.
Solution
class Solution {
public int networkDelayTime(int[][] times, int N, int K) {
HashMap<Integer,List<int[]>> map = new HashMap();
for(int[] pair : times){
if(!map.containsKey(pair[0])){
map.put(pair[0],new ArrayList());
}
map.get(pair[0]).add(new int[]{pair[1],pair[2]});
}
//sorted by their distance to the start point.
PriorityQueue<int[]> q = new PriorityQueue<int[]>((a,b)->(a[1]-b[1]));
HashSet<Integer> visited = new HashSet();
q.add(new int[]{K,0});
int res = 0;
while(!q.isEmpty()){
int[] cur = q.poll();
//this will skip the nodes with larger distance, so we can ensure that the node will always be visited by smallest distance.
if(visited.contains(cur[0])) continue;
visited.add(cur[0]);
//distance from current node to the start.
res = cur[1];
N--;
//means this node has next.
if(map.containsKey(cur[0])){
for(int[] next : map.get(cur[0])){
//set distance of next nodes.
q.add(new int[]{next[0],cur[1]+next[1]});
}
}
}
return N==0?res:-1;
}
}