- 多线程
- 线程Thread
- 如何确保多线程安全
- 解决多线程安全
- Synchronized and Lock
- 线程池 ThreadPool
- 死锁
- 线程常用工具类
- Atomic
- ThreadLocal
- Volatile
多线程
进程是程序的一次执行,进程是一个程序及其数据在处理机上顺序执行时所发生的活动,进程是 具有独立功能的程序在一个数据集合上运行的过程,它是系统进行资源分配和调度的一个独立单位
- 进程是系统进行资源分配和调度的独立单位。每一个进程都有它自己的内存空间和系统资源
进程实现多处理机环境下的进程调度,分派,切换时,都需要花费较大的时间和空间开销 引入线程主要是为了提高系统的执行效率,减少处理机的空转时间和调度切换的时间,以及便于系统管理。使OS具有更好的并发性。
在同一个进程内又可以执行多个任务,而这每一个任务我就可以看出是一个线程。 所以说:一个进程会有1个或多个线程的!
- 进程作为资源分配的基本单位
- 线程作为资源调度的基本单位,是程序的执行单元,执行路径(单线程:一条执行路径,多线程: 多条执行路径)。是程序使用CPU的最基本单位。
线程有3个基本状态: 执行、就绪、阻塞
线程有5种基本操作: 派生、阻塞、激活、 调度、 结束
并行与并发
并行:
- 并行性是指同一时刻内发生两个或多个事件。
- 并行是在不同实体上的多个事件
并发:
- 并发性是指同一时间间隔内发生两个或多个事件。
- 并发是在同一实体上的多个事件
并行是针对进程的,并发是针对线程的。
线程Thread
- 继承Thread,重写run方法
- 实现Runnable接口,重写run方法
- 实现Callable接口,重写run方法
public class MyThread extends Thread {
@Override
public void run() {
for (int x = 0; x < 200; x++) {
System.out.println(x);
}
}
}
public class MyThreadDemo {
public static void main(String[] args) {
// 创建两个线程对象
MyThread my1 = new MyThread(); MyThread my2 = new MyThread();
my1.start();
my2.start();
}
}
Runnable/Callable
public class MyRunnable implements Runnable {
@Override
public void run() {
for (int x = 0; x < 100; x++) {
System.out.println(x);
}
}
}
public class MyRunnableDemo {
public static void main(String[] args) {
// 创建MyRunnable类的对象 MyRunnable my = new MyRunnable();
Thread t1 = new Thread(my);
Thread t2 = new Thread(my);
t1.start();
t2.start();
}
}
使用实现Runnable接口更优:
- 可以避免java中的单继承的限制
- 应该将并发运行任务和运行机制解耦,因此我们选择实现Runnable接口这种方式!
不要将 run() 和 start() 搞混
- run()和start()方法区别:
- run() :仅仅是封装被线程执行的代码,直接调用是普通方法
- start() :首先启动了线程,然后再由jvm去调用该线程的run()方法。
- jvm虚拟机的启动是单线程的还是多线程的?
- 是多线程的。不仅仅是启动main线程,还至少会启动垃圾回收线程的
守护线程
守护线程是为其他线程服务的
- 垃圾回收线程就是守护线程
守护线程有一个特点: 当别的用户线程执行完了,虚拟机就会退出,守护线程也就会被停止掉了。
也就是说:守护线程作为一个服务线程,没有服务对象就没有必要继续运行了。
守护线程中产生的新线程也是守护线程
线程优先级
线程优先级高仅仅表示线程获取的CPU时间片的几率高,但这不是一个确定的因素!
线程的优先级是高度依赖于操作系统的,Windows和Linux就有所区别(Linux下优先级可能就被忽略了)
生命周期
线程有3个基本状态:执行、就绪、阻塞
sleep()
调用sleep方法会进入计时等待状态,等时间到了,进入的是就绪状态而并非是运行状态!
yield()
调用yield方法会先让别的线程执行,但是不确保真正让出。
我有空,可以的话,让你们先执行
join()
调用join方法,会等待该线程执行完毕后才执行别的线程~
interrupt()
线程中断在之前的版本有stop方法,但是被设置过时了。
现在已经没有强制线程终止的方法了!
由于stop方法可以让一个线程A终止掉另一个线程B
- 被终止的线程B会立即释放锁,这可能会让对象处于不一致的状态。
- 线程A也不知道线程B什么时候能够被终止掉,万一线程B还处理运行计算阶段,线程A调用stop方 法将线程B终止,那就很无辜
总而言之,Stop方法太暴力了,不安全,所以被设置过时了。
我们一般使用的是interrupt来请求终止线程
-
要注意的是:interrupt不会真正停止一个线程,它仅仅是给这个线程发了一个信号告诉它,它应 该要结束了(明白这一点非常重要!)
-
也就是说:Java设计者实际上是想线程自己来终止,通过上面的信号,就可以判断处理什么业务了。
-
具体到底中断还是继续运行,应该由被通知的线程自己处理.
调用interrupt()并不是要真正终止掉当前线程,仅仅是设置了一个中断标志。这个中断标志 可以给我们用来判断什么时候该干什么活!什么时候中断由我们自己来决定,这样就可以安全地终止线程了!
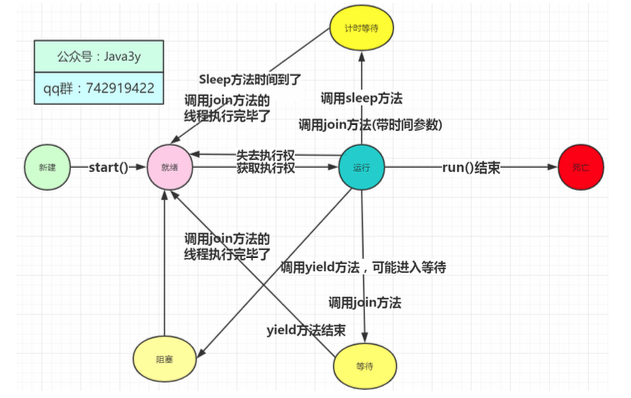
interrupt方法压根是不会对线程的状态造成影响的,它仅仅设置一个标志位罢了
Synchronized
为保证线程安全,最简单的方式:如果我们在service方法上加上JDK 为我们提供的内置锁synchronized,那么我们就可以实现线程安全了。
public void synchronized service(ServletRequest servletRequest,ServletResponse servletResponse) throws ServletException, IOException {
++count;
// To something else...
}
但是这会带来很严重的性能问题: 每个请求都得等待上一个请求的service方法处理了以后才可以完成对应的操作
在使用多线程的时候:更严重的时候还有死锁(程序就卡住不动了)。
如何确保多线程安全
虽然实现了线程安全了,但是这会带来很严重的性能问题:
- 每个请求都得等待上一个请求的service方法处理了以后才可以完成对应的操作
这就导致了:我们完成一个小小的功能,使用了多线程的目的是想要提高效率,但现在没有把握得当,却带来严重的性能问题!
解决多线程安全
一般会有下面这么几种办法来实现线程安全问题:
-
无状态(没有共享变量)
-
使用final使该引用变量不可变(如果该对象引用也引用了其他的对象,那么无论是发布或者使用时都需要加锁)
-
加锁(内置锁,显示Lock锁) 使用JDK为我们提供的类来实现线程安全(此部分的类就很多了)
-
原子性(就比如上面的 count++ 操作,可以使用AtomicLong来实现原子性,那么在增加的 时候就不会出差错了!)
-
容器(ConcurrentHashMap等等…)
原子性
count++ ,先读取,后自增,再赋值。如果该操作是原子性的,那么就可以说线程安全了(因为没有中间的三部环节,一步到位【原子性】
原子性就是执行某一个操作是不可分割的。
可见性 (Volatile)
可以简单认为: volatile是一种轻量级的同步机制
volatile仅仅用来保证该变量对所有线程的可⻅性,但不保证原子性
- 保证该变量对所有线程的可⻅性
- 在多线程的环境下:当这个变量修改时,所有的线程都会知道该变量被修改了,也就是所谓的“可⻅性”
- 不保证原子性
- 修改变量(赋值)实质上是在JVM中分了好几步,而在这几步内(从装载变量到修改),它是不安全的。
使用了volatile修饰的变量保证了三点:
-
一旦你完成写入,任何访问这个字段的线程将会得到最新的值
-
在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可⻅的,因为内存屏障会把之前的写入值都刷新到缓存。
-
volatile可以防止重排序(重排序指的就是:程序执行的时候,CPU、编译器可能会对执行顺序做一 些调整,导致执行的顺序并不是从上往下的。从而出现了一些意想不到的效果)。而如果声明了volatile,那么CPU、编译器就会知道这个变量是共享的,不会被缓存在寄存器或者其他不可⻅的地方。
一般来说,volatile大多用于标志位上(判断操作),满足下面的条件才应该使用volatile修饰变量:
-
修改变量时不依赖变量的当前值(因为volatile是不保证原子性的)
-
该变量不会纳入到不变性条件中(该变量是可变的)
-
在访问变量的时候不需要加锁(加锁就没必要使用volatile这种轻量级同步机制了)
线程封闭
只要我们保证不要在栈(方法)上发布对象(每个变量的作用域仅仅停留在当前的方法上), 那么我们的线程就是安全的。
使用ThreadLocal可以保证每个线程独占自己的变量。
不变性
final仅仅是不能修改该变量的引用,但是引用里边的数据是可以改的!
final HashMap<Person> hashMap = new HashMap<>();
hashMap是一个不可变的对象引用,但是引用内部的数据是可以改的。
要想将对象设计成不可变对象,那么要满足下面三个条件:
- 对象创建后状态就不能修改
- 对象所有的域都是final修饰的
- 对象是正确创建的(没有this引用逸出)
线程安全性委托
使用工具类实现线程安全:ConcurrentHashMap,AtomicInt
Synchronized and Lock
Java多线程加锁机制,有两种:
Synchronized & 显式Lock
Synchronized
public synchronized void test() {
// doSomething
}
synchronized是一种互斥锁, 一次只能允许一个线程进入被锁住的代码块
synchronized是一种内置锁/监视器锁
Java中每个对象都有一个内置锁(监视器,也可以理解成锁标记),而synchronized就是使用对象的内置锁(监视器)来将代码块(方法)锁定的! (锁的是对象,但我们同步的是方法/代码块)
synchronized保证了线程的原子性。(被保护的代码块是一次被执行的,没有任何线程会同时访问)
synchronized还保证了可⻅性。(当执行完synchronized之后,修改后的变量对其他的线程是可⻅的)
Java中的synchronized,通过使用内置锁,来实现对变量的同步操作,进而实现了对变量操作的原子性和其他线程对变量的可⻅性,从而确保了并发情况下的线程安全。
可重入性
因为锁的持有者是“线程”,而不是“调用”。线程A已经是有了实例对象的锁了,当再需要的时候可以继续“开锁”进去的!
因此持有锁的是线程,内置锁是可重入的。
释放
-
当方法(代码块)执行完毕后会自动释放锁,不需要做任何的操作。
-
当一个线程执行的代码出现异常时,其所持有的锁会自动释放。
不会由于异常导致出现死锁现象~
Lock显式锁
-
Lock方式来获取锁支持中断、超时不获取、是非阻塞的
-
提高了语义化,哪里加锁,哪里解锁都得写出来
-
Lock显式锁可以给我们带来很好的灵活性,但同时我们必须手动释放锁
-
支持Condition条件对象
-
允许多个读线程同时访问共享资源
Lock锁在刚出来的时候很多性能方面都比Synchronized锁要好,但是从JDK1.6开始 Synchronized锁就做了各种的优化(毕竟亲儿子,牛逼)
优化操作:适应自旋锁,锁消除,锁粗化,轻量级锁,偏向锁。
所以,到现在Lock锁和Synchronized锁的性能其实差别不是很大!
而Synchronized锁用起来又特别简单。Lock锁还得顾忌到它的特性,要手动释放锁才行(如果忘了释放,这就是一个隐患)
所以说,我们绝大部分时候还是会使用Synchronized锁,用到了Lock锁提及的特性,带来的灵活性才会考虑使用Lock显式锁
公平锁
公平锁: 线程将按照它们发出请求的顺序来获取锁
非公平锁: 线程发出请求的时可以“插队”获取锁
Lock和synchronize都是默认使用非公平锁的。
如果不是必要的情况下,不要使用公平锁,因为公平锁会来带一些性能的消耗。
AQS (AbstractQueuedSynchronizer)
Lock的子类实现都是基于AQS的。
-
AQS其实就是一个可以给我们实现锁的框架
-
内部实现的关键是:先进先出的队列、state状态
-
定义了内部类ConditionObject
- 拥有两种线程模式
- 独占模式
- 共享模式
-
在LOCK包中的相关锁(常用的有ReentrantLock、 ReadWriteLock)都是基于AQS来构建
- 一般我们叫AQS为同步器
ReentrantLock & ReentrantReadWriteLock
ReentrantLock
-
比synchronized更有伸缩性(灵活)
-
支持公平锁(是相对公平的)
-
使用时最标准用法是在try之前调用lock方法,在finally代码块释放锁
class X {
private final ReentrantLock lock = new ReentrantLock();
// ...
public void m() {
lock.lock();
// block until condition holds
try {
// ... method body
} finally {
lock.unlock();
}
}
}
AQS是ReentrantLock的基础,AQS是构建 锁、同步器的框架
非公平Lock:尝试获取锁,获取失败的话就调用AQS的 acquire(1) 方法
公平Lock:多了一个状态条件:判断当前线程是否位于CLH同步队列中的第一个。如果是则返回flase,否则返回 true。
ReentrantReadWriteLock
synchronized内置锁和ReentrantLock都是互斥锁(一次只能有一个线程进入到临界区(被锁定的区域))
而ReentrantReadWriteLock是一个读写锁:
-
在读取数据的时候,可以多个线程同时进入到到临界区(被锁定的区域)
-
在写数据的时候,无论是读线程还是写线程都是互斥的
一般来说:我们大多数都是读取数据得多,修改数据得少。所以这个读写锁在这种场景下就很有用。
-
读锁不支持条件对象,写锁支持条件对象
-
读锁不能升级为写锁,写锁可以降级为读锁
-
读写锁也有公平和非公平模式
-
读锁支持多个读线程进入临界区,写锁是互斥的
Summary
-
AQS是ReentrantReadWriteLock和ReentrantLock的基础,因为默认的实现都是在内部类Syn中, 而Syn是继承AQS的~
-
ReentrantReadWriteLock和ReentrantLock都支持公平和非公平模式,公平模式下会去看FIFO队列线程是否是在队头,而非公平模式下是没有的
-
ReentrantReadWriteLock是一个读写锁,如果读的线程比写的线程要多很多的话,那可以考虑使用它。它使用state的变量高16位是读锁,低16位是写锁
-
写锁可以降级为读锁,读锁不能升级为写锁
-
写锁是互斥的,读锁是共享的。
线程池 ThreadPool
为每个请求都开一个新的线程虽然理论上是可以的,但是会有缺点:
-
线程生命周期的开销非常高。每个线程都有自己的生命周期,创建和销毁线程所花费的时间和资源 可能比处理客户端的任务花费的时间和资源更多,并且还会有某些空闲线程也会占用资源。
-
程序的稳定性和健壮性会下降,每个请求开一个线程。如果受到了恶意攻击或者请求过多(内存不足),程序很容易就奔溃掉了。
线程最好是交由线程池来管理
JDK提供Excutor框架来使用线程池,它是线程池的基础。
Executor提供了一种将“任务提交”与“任务执行”分离开来的机制(解耦)
Callable & Future
Future<?> submit(Runnable task)
<T> Future<T> submit(Callable<T> task)
Callable就是Runnable的扩展。
-
Runnable没有返回值,不能抛出受检查的异常,而Callable可以!
-
当我们的任务需要返回值的时,我们就可以使用Callable!
-
Future一般我们认为是Callable的返回值,但他其实代表的是任务的生命周期(当然了,它是能获取得到 Callable的返回值的)
ThreadPoolExecutor
public class ThreadPoolExecutor extends AbstractExecutorService {
/**
* The main pool control state, ctl, is an atomic integer packing
* two conceptual fields
* workerCount, indicating the effective number of threads
* runState, indicating whether running, shutting down etc
*
* In order to pack them into one int, we limit workerCount to
* (2^29)-1 (about 500 million) threads rather than (2^31)-1 (2
* billion) otherwise representable. If this is ever an issue in
* the future, the variable can be changed to be an AtomicLong,
* and the shift/mask constants below adjusted. But until the need
* arises, this code is a bit faster and simpler using an int.
*
* The workerCount is the number of workers that have been
* permitted to start and not permitted to stop. The value may be
* transiently different from the actual number of live threads,
* for example when a ThreadFactory fails to create a thread when
* asked, and when exiting threads are still performing
* bookkeeping before terminating. The user-visible pool size is
* reported as the current size of the workers set.
*
* The runState provides the main lifecycle control, taking on values:
*
* RUNNING: Accept new tasks and process queued tasks
* SHUTDOWN: Don't accept new tasks, but process queued tasks
* STOP: Don't accept new tasks, don't process queued tasks,
* and interrupt in-progress tasks
* TIDYING: All tasks have terminated, workerCount is zero,
* the thread transitioning to state TIDYING
* will run the terminated() hook method
* TERMINATED: terminated() has completed
*
* The numerical order among these values matters, to allow
* ordered comparisons. The runState monotonically increases over
* time, but need not hit each state. The transitions are:
*
* RUNNING -> SHUTDOWN
* On invocation of shutdown(), perhaps implicitly in finalize()
* (RUNNING or SHUTDOWN) -> STOP
* On invocation of shutdownNow()
* SHUTDOWN -> TIDYING
* When both queue and pool are empty
* STOP -> TIDYING
* When pool is empty
* TIDYING -> TERMINATED
* When the terminated() hook method has completed
*
* Threads waiting in awaitTermination() will return when the
* state reaches TERMINATED.
*
* Detecting the transition from SHUTDOWN to TIDYING is less
* straightforward than you'd like because the queue may become
* empty after non-empty and vice versa during SHUTDOWN state, but
* we can only terminate if, after seeing that it is empty, we see
* that workerCount is 0 (which sometimes entails a recheck -- see
* below).
*/
}
-
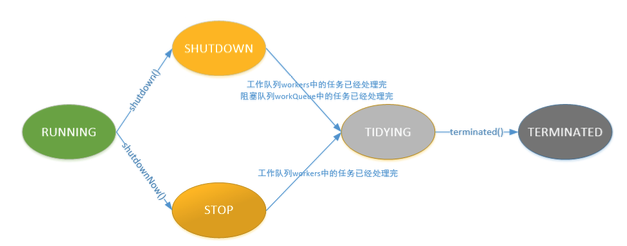
RUNNING:线程池能够接受新任务,以及对新添加的任务进行处理。
-
SHUTDOWN:线程池不可以接受新任务,但是可以对已添加的任务进行处理。
-
STOP:线程池不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
-
TIDYING:当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
-
TERMINATED:线程池彻底终止的状态。
{kind=link}
参数
-
指定核心线程数量
-
指定最大线程数量
-
允许线程空闲时间
-
时间对象
-
阻塞队列
-
线程工厂
-
任务拒绝策略
参数要点
-
线程数量要点:
-
如果运行线程的数量少于核心线程数量,则创建新的线程处理请求
-
如果运行线程的数量大于核心线程数量,小于最大线程数量,则当队列满的时候才创建新的线程
-
如果核心线程数量等于最大线程数量,那么将创建固定大小的连接池
-
如果设置了最大线程数量为无穷,那么允许线程池适合任意的并发数量
-
-
线程空闲时间要点:
- 当前线程数大于核心线程数,如果空闲时间已经超过了,那该线程会销毁。
-
排队策略要点:
-
同步移交:不会放到队列中,而是等待线程执行它。如果当前线程没有执行,很可能会新开一个线程执行。
-
无界限策略:如果核心线程都在工作,该线程会放到队列中。所以线程数不会超过核心线程数
-
有界限策略:可以避免资源耗尽,但是一定程度上减低了吞吐量
-
-
当线程关闭或者线程数量满了和队列饱和了,就有拒绝任务的情况,拒绝任务策略:
-
直接抛出异常
-
使用调用者的线程来处理
-
直接丢掉这个任务
-
丢掉最老的任务
-
线程池关闭
-
调用shutdown()后,线程池状态立刻变为SHUTDOWN,而调用shutdownNow(),线程池状态立刻变为STOP。
-
shutdown()等待任务执行完才中断线程,而shutdownNow()不等任务执行完就中断了线程。
死锁
要出现死锁问题需要满足以下条件:
-
互斥条件:一个资源每次只能被一个线程使用。
-
请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
-
不剥夺条件:线程已获得的资源,在未使用完之前,不能强行剥夺。
-
循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。
造成死锁的原因可以概括成三句话:
-
当前线程拥有其他线程需要的资源
-
当前线程等待其他线程已拥有的资源
-
都不放弃自己拥有的资源
死锁类型
3种典型的死锁类型:
静态锁顺序死锁,动态锁顺序死锁,协作对象死锁。
静态锁顺序死锁
a和b两个方法都需要获得A锁和B锁。一个线程执行a方法且已经获得了A锁,在等待B锁;另一个线程执行了b方法且已经获得了B锁,在等待A锁。这种状态,就是发生了静态的锁顺序死锁。
解决静态的锁顺序死锁的方法就是:所有需要多个锁的线程,都要以相同的顺序来获得锁。
//solution for StaticLockOrderDeadLock
class StaticLockOrderDeadLock{
private final Object lockA=new Object();
private final Object lockB=new Object();
public void a(){
synchronized (lockA) {
synchronized (lockB) {
System.out.println("function a");
}
}
}
public void b(){
//acquire the lock in the same order
synchronized (lockA) {
synchronized (lockB) {
System.out.println("function b");
}
}
}
}
动态锁顺序死锁
动态的锁顺序死锁是指两个线程调用同一个方法时,传入的参数颠倒造成的死锁。
如下代码,一个线程调用了transferMoney方法并传入参数accountA,accountB;
另一个线程调用了transferMoney方法并传入参数accountB,accountA。
此时就可能发生在静态的锁顺序死锁中存在的问题
即:第一个线程获得了accountA锁并等待accountB锁,第二个线程获得了accountB锁并等待accountA锁。
//可能发生动态锁顺序死锁的代码
class DynamicLockOrderDeadLock{
public void transefMoney(Account fromAccount,Account toAccount,Double amount){
synchronized (fromAccount) {
synchronized (toAccount) {
//...
fromAccount.minus(amount);
toAccount.add(amount);
//...
}
}
}
}
动态的锁顺序死锁解决方案如下:使用System.identifyHashCode来定义锁的顺序。确保所有的线程都以相同的顺序获得锁
协作对象间死锁
两个相互协作的类之间的死锁,比如下面的代码:
一个线程调用了Taxi对象的setLocation方法,另一个线程调用了Dispatcher对象的getImage方法。
此时可能会发生,第一个线程持有Taxi对象锁并等待Dispatcher对象锁,另一个线程持有Dispatcher对象锁并等待Taxi对象锁。
class Taxi {
@GuardedBy("this")private Point location, destination;
private final Dispatcher dispatcher;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
/** 获取出租车的位置 **/
public synchronized Point getLocation() {
return location;
}
/** 设置出租车的位置 **/
public synchronized void setLocation(Point location) {
this.location = location;
if (location.equals(distination)) {
dispatcher.notifyAvailable(this);
}
}
}
class Dispatcher {
@GuardedBy("this") private final Set<Taxi> taxis;
@GuardedBy("this") private final Set<Taxi> availableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
availableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvailable(Taxi taxi) {
availableTaxis.add(taxi);
}
/** 获取某个时刻,整个车队的完整快照 **/
public synchronized Image getImage() {
Image image = new Image();
for (Taxi t : taxis) {
image.drawMarker(t.getLocation());
}
return image;
}
}
setLocation和notifyAvailable方法都是同步方法,调用setLocation的线程首先获取Taxi上的锁,然后获取Dispatcher的锁。
getImage方法先获取Dispatcher上的锁,再获取Taxi上的锁,这两个方法被不同的线程调用时容易产生死锁。
class Taxi {
@GuardedBy("this")private Point location, destination;
private final Dispatcher dispatcher;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
/** 获取出租车的位置 **/
public synchronized Point getLocation() {
return location;
}
/** 设置出租车的位置 **/
public void setLocation(Point location) {
boolean reachedDestination = false;
/** 缩小缩的范围 把方法变成开放调用 **/
synchronized(this) {
this.location = location;
reachedDestination = location.equals(distination);
}
if (reachedDestination) {
dispatcher.notifyAvailable(this);
}
}
}
class Dispatcher {
@GuardedBy("this") private final Set<Taxi> taxis;
@GuardedBy("this") private final Set<Taxi> availableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
availableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvailable(Taxi taxi) {
availableTaxis.add(taxi);
}
/** 获取每辆出租车不同时刻的位置 **/
public Image getImage() {
Set<Taxi> copy;
synchronized(this) {
copy = new HashSet<Taxi>(taxis);
}
Image image = new Image();
for (Taxi t : taxis) {
image.drawMarker(t.getLocation());
}
return image;
}
}
通过上面的改造,setLocation和getImage都变成了开放调用,与那些持有锁时调用外部方法的程序相比,更容易对依赖的开发调用的程序进行死锁分析。
本质
开放调用的本质是加锁范围最小化。
避免死锁
避免死锁可以概括成三种方法:
- 固定加锁的顺序(针对锁顺序死锁)
- 如果所有线程以固定的顺序来获得锁,那么程序中就不会出现锁顺序死锁问题!
-
开放调用(针对对象之间协作造成的死锁) -> 最小化加锁范围
- 使用定时锁–> tryLock()
- 如果等待获取锁时间超时,则抛出异常而不是一直等待!
使用死锁检测
JDK提供了两种方式来给我们检测:
-
JconsoleJDK自带的图形化界面工具,使用JDK给我们的的工具JConsole
-
Jstack是JDK自带的命令行工具,主要用于线程Dump分析。
线程常用工具类
均用于解决线程之间的通讯问题
CountDownLatch
A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.
CountDownLatch是一个同步的辅助类,允许一个或多个线程一直等待,直到其它线程完成它们的操作。
- count初始化CountDownLatch,然后需要等待的线程调用await方法。
await方法会一直受阻塞直到count=0。
而其它线程完成自己的操作后,调用 countDown() 使计数器count减1。
当count减到0时,所有在等待的线程均会被释放
通过count变量来控制等待,如果count值为0了(其他线程的任务都完成了),就可以继续执行。
import java.util.concurrent.CountDownLatch;
public class Test {
public static void main(String[] args) {
final CountDownLatch countDownLatch = new CountDownLatch(5);
System.out.println("现在6点下班了.....");
// Me线程启动
new Thread(new Runnable() {
@Override
public void run() {
try {
// 这里调用的是await()不是wait()
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("...其他的5个员工走光了,Me终于可以走了");
}
}).start();
// 其他员工线程启动
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("员工xxxx下班了");
countDownLatch.countDown();
}
}).start();
}
}
}
CyclicBarrier
A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point. CyclicBarriers are useful in programs involving a fixed sized party of threads that must occasionally wait for each other. The barrier is called cyclic because it can be re-used after the waiting threads are released.
在某一处地点相互等待
CyclicBarrier允许一组线程互相等待,直到到达某个公共屏障点。
叫做cyclic是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用(对比于CountDownLatch是不能重用的)
CountDownLatch注重的是等待其他线程完成,CyclicBarrier注重的是:当线程到达某个状态后,暂停下来等待其他线程,所有线程均到达以后,继续执行。
import java.util.concurrent.CyclicBarrier;
public class Test {
public static void main(String[] args) {
final CyclicBarrier CyclicBarrier = new CyclicBarrier(2);
for (int i = 0; i < 2; i++) {
new Thread(() -> {
String name = Thread.currentThread().getName();
if (name.equals("Thread-0")) {
name = "guanzhou";
} else {
name = "女朋友";
}
System.out.println(name + "到了龙翔桥");
try {
// 两个人都要到体育⻄才能发朋友圈 CyclicBarrier.await();
// 他俩到达了龙翔桥,看⻅了对方发了一条朋友圈: System.out.println("跟" + name + "去in77吃东⻄~");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
Semaphore
Semaphores are often used to restrict the number of threads than can access some (physical or logical) resource.
Semaphore(信号量)实际上就是可以控制同时访问的线程个数,它维护了一组”许可证”。
-
当调用 acquire() 方法时,会消费一个许可证。如果没有许可证了,会阻塞起来
-
当调用 release() 方法时,会添加一个许可证。
-
这些”许可证”的个数其实就是一个count变量罢了~
import java.util.concurrent.Semaphore;
public class Test {
public static void main(String[] args) { // 假设有50个同时来到奶茶店⻔口
int nums = 50;
// 奶茶店只能容纳5个人同时挑选酸奶
Semaphore semaphore = new Semaphore(5);
for (int i = 0; i < nums; i++) {
int finalI = i;
new Thread(() -> {
try {
// 叫到"号"的才能进酸奶店挑选购买 semaphore.acquire();
System.out.println("顾客" + finalI + "在挑选商品,购买...");
// 假设挑选了xx⻓时间,购买了
Thread.sleep(1000);
// 归还一个许可,后边的就可以进来购买了
System.out.println("顾客" + finalI + "购买完毕了...");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}
Summary
- CountDownLatch(闭锁)
- 某个线程等待其他线程执行完毕后,它才执行(其他线程等待某个线程执行完毕后,它才执行)
- CyclicBarrier(栅栏)
- 一组线程互相等待至某个状态,这组线程再同时执行。
- Semaphore(信号量)
- 控制一组线程同时执行。
Atomic
CAS (Compare and Swap)
比较并交换(compare and swap, CAS),是原子操作的一种,可用于在多线程编程中实现不被打断 的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预 知性产生的数据不一致问题。
该操作通过将内存中的值与指定数据进行比较,当数值一样时将内 存中的数据替换为新的值。
CAS有3个操作数: 内存值V 旧的预期值A 要修改的新值B
当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值(A和内存值V相同时,将内存值V修改为B),而其它线程都失败
失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试(或者什么都不做)。

-
IF V== A, Set V = B
-
IF V != A, retry(自旋)/do nothing
CAS是原子性的,虽然可能看到比较后再修改(compare and swap)觉得会有两个操作,但终究是原子性的!
Atomic包的类的实现绝大调用Unsafe的方法,而Unsafe底层实际上是调用C代码,C代码调用汇编,最后生成出一条CPU指令cmpxchg,完成操作。
这也就为什么CAS是原子性的,因为它是一条CPU指令,不会被打断。
LongAdder
如果是 JDK8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好(减少乐观锁的重试次数)。
- 使用AtomicLong时,在高并发下大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS会成功,所以其他线程会不断尝试自旋尝试CAS操作,这会浪费不少的CPU资源。
而LongAdder可以概括成这样:内部核心数据value分离成一个数组(Cell),每个线程访问时,通过哈希等算法映射到其中一个数字进行计数,而最终的计数结果,则为这个数组的求和累加。
简单来说就是将一个值分散成多个值,在并发的时候就可以分散压力,性能有所提高。
ThreadLocal
/**
* This class provides thread-local variables. These variables differ from *
their normal counterparts in that each thread that accesses one (via its
* {@code get} or {@code set} method) has its own, independently initialized
* copy of the variable. {@code ThreadLocal} instances are typically private
* static fields in classes that wish to associate state with a thread (e.g.,
* a user ID or Transaction ID).
*
* <p>For example, the class below generates unique identifiers local to each
* thread.
* A thread's id is assigned the first time it invokes {@code ThreadId.get()}
* and remains unchanged on subsequent calls. */
ThreadLocal提供了线程的局部变量,每个线程都可以通过 set() 和 get() 来对这个局部变量进行操作,但不会和其他线程的局部变量进行冲突,实现了线程的数据隔离
往ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的。
避免参数传递
避免一些参数的传递的理解可以参考一下Cookie和Session:
每当我访问一个⻚面的时候,浏览器都会帮我们从硬盘中找到对应的Cookie发送过去。
浏览器是十分聪明的,不会发送别的网站的Cookie过去,只带当前网站发布过来的Cookie过去
浏览器就相当于我们的ThreadLocal,它仅仅会发送我们当前浏览器存在的Cookie(ThreadLocal的局部 变量),不同的浏览器对Cookie是隔离的
(Chrome,Opera,IE的Cookie是隔离的【在Chrome登陆了,在 IE你也得重新登陆】)
同样地:线程之间ThreadLocal变量也是隔离的….
ThreadLocal实现
ThreadLocalMap是ThreadLocal的一个内部类。用Entry类来进行存储
值都是存储到这个Map上的,key是当前ThreadLocal对象! 如果该Map不存在,则初始化一个。
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
ThreadLocalMap是在ThreadLocal中使用内部类来编写的,但对象的引用是在Thread中!
Thread为每个线程维护了ThreadLocalMap这么一个Map,而ThreadLocalMap的key是LocalThread对象本身,value则是要存储的对象
Summary
-
每个Thread维护着一个ThreadLocalMap的引用
-
ThreadLocalMap是ThreadLocal的内部类,用Entry来进行存储
-
调用ThreadLocal的set()方法时,实际上就是往ThreadLocalMap设置值,key是ThreadLocal对 象,值是传递进来的对象
-
调用ThreadLocal的get()方法时,实际上就是往ThreadLocalMap获取值,key是ThreadLocal对象
-
ThreadLocal本身并不存储值,它只是作为一个key来让线程从ThreadLocalMap获取value。
正因为这个原理,所以ThreadLocal能够实现“数据隔离”,获取当前线程的局部变量值,不受其他线程 影响~
Volatile
Volatile可以看做是轻量级的 Synchronized,它只保证了共享变量的可见性。
在线程 A 修改被 volatile 修饰的共享变量之后,线程 B 能够读取到正确的值。
java 在多线程中操作共享变量的过程中,会存在指令重排序与共享变量工作内存缓存的问题。
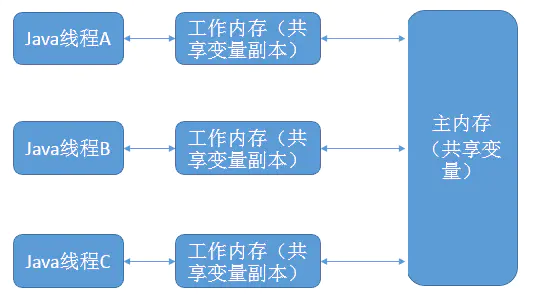
Java内存模型规定了所有的变量都存储在主内存中。
每条线程中还有自己的工作内存,线程的工作内存中保存了被该线程所使用到的变量(这些变量是从主内存中拷贝而来)。
线程对变量的所有操作(读取,赋值)都必须在工作内存中进行。
不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
原理
java 语言提供了一种稍弱的同步机制,Volatile可以看做是轻量级的 Synchronized,即volatile变量,用来将变量的更新操作通知到其他线程。
当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将该变量上的操作与其他内存操作一起重排序。
volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值。
在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比sychronized关键字更轻量级的同步机制。
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到CPU缓存中。
如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。
而声明变量是 volatile 的,JVM 保证了每次读变量都从内存中读,跳过 CPU cache 这一步。
Volatile三个特征
可见性
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这段代码会完全运行正确么?即一定会将线程中断么?
不一定
也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效
然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。那么线程1读取到的就是最新的正确的值。
原子性
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for (int i = 0; i < 10; i++) {
new Thread() {
public void run() {
for (int j = 0; j < 1000; j++) {
test.increase();
}
}
;
}.start();
}
while (Thread.activeCount() > 1) //保证前面的线程都执行完
{
Thread.yield();
}
System.out.println(test.inc);
}
}
事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。
可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的
它包括读取变量的原始值、进行加1操作、写入工作内存。
那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,也不会导致主存中的值刷新
所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。
解决方案:可以通过synchronized或lock,进行加锁,来保证操作的原子性,也可以通过AtomicInteger。
在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类,即对基本数据类型的 自增(加1操作),自减(减1 操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。
atomic是利用CAS来实现原子性操作的(Compare And Swap),CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。
volatile保证有序性
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量的读操作或者写操作的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
//x、y为非volatile变量
// flag为volatile变量
x=2; //语句1
y=0; //语句2
flag=true; //语句3
x=4; //语句4
y=-1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,
不会将语句3放到语句1、语句2前面
也不会讲语句3放到语句4、语句5后面。
但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,
且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
实现原理
处理器为了提高处理速度,不直接和内存进行通讯,而是将系统内部的数据读到内部缓存后在进行操作,但操作完之后不知道什么时候会写入内存。
如果对声明了volatile变量进行写操作时,JVM会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写会到系统内存。
这一步确保了如果有其他线程对声明了volatile变量进行修改,则立即更新主内存中数据。
但这时候其他处理器的缓存还是旧的,所以在多处理器环境下,为了保证各个处理器缓存一致,每个处理会通过嗅探在总线上传播的数据来检查自己的缓存是否过期,当处理器发现自己缓存行对应的内存地址被修改了,就会将当前处理器的缓存行设置成无效状态
当处理器要对这个数据进行修改操作时,会强制重新从系统内存把数据读到处理器缓存里。
这一步确保了其他线程获得的声明了volatile变量都是从主内存中获取最新的。
Lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;
即在执行到内存屏障这句指令时,在它前面的操作已经全部完成。
Summary
-
volatile修饰符适用于以下场景:某个属性被多个线程共享,其中有一个线程修改了此属性,其他线程可以立即得到修改后的值,比如
boolean flag;或者作为触发器,实现轻量级同步。 -
volatile属性的读写操作都是无锁的,它不能替代synchronized,因为它没有提供原子性和互斥性。因为无锁,不需要花费时间在获取锁和释放锁_上,所以说它是低成本的。
-
volatile只能作用于属性,我们用volatile修饰属性,这样compilers就不会对这个属性做指令重排序。
-
volatile提供了可见性,任何一个线程对其的修改将立马对其他线程可见,volatile属性不会被线程缓存,始终从主存中读取。
-
volatile提供了happens-before保证,对volatile变量v的写入happens-before所有其他线程后续对v的读操作。
-
volatile可以使得long和double的赋值是原子的。
-
volatile可以在单例双重检查中实现可见性和禁止指令重排序,从而保证安全性。